Even a simple example using Spark Streaming doesn’t quite feel complete without the use of Kafka as the message hub. More and more use cases rely on Kafka for message transportation. By taking a simple streaming example (Spark Streaming – A Simple Example source at GitHub) together with a fictive word count use case this post describes the different ways to add Kafka to a Spark Streaming application. Additionally this posts describes the possibility to write out results to HBase from Spark directly using the TableOutputFormat.
Kafka as DStream
For data collection from incoming sources Spark Streaming uses special Receiver tasks executed inside an Executor on one or more worker nodes. The diagram below shows how this might could look like with one Receiver running on one node and replicating each received data to two nodes. Blocks are created from the stream an turned into RDD partitions by the batch interval. How many blocks will be created is determined by the spark.streaming.blockInterval. The receiver in Spark Streaming can be a source of unreliable data transportation and needs careful considerations. Originally the Kafka Receiver had little possibilities to persist it’s state, so in the case of the worker node with the receiver crashing, although the block would have been replicated, there was no way to possibly know which data has already been received.
The receiver in Spark Streaming can be a source of unreliable data transportation and needs careful considerations. Originally the Kafka Receiver had little possibilities to persist it’s state, so in the case of the worker node with the receiver crashing, although the block would have been replicated, there was no way to possibly know which data has already been received.
If the driver in such a scenario would die it would also kill all the other executors, hence every receiver. Spark 1.3 started to address this scenarios with a Spark Streaming WAL (write-ahead-log), checkpointing (necessary for stateful operations), and a new (yet experimental) Kafka DStream implementation, that does not make use of a receiver.
import org.apache.spark.streaming.kafka._
val directKafkaStream = KafkaUtils.createDirectStream[
[key class], [value class], [key decoder class], [value decoder class] ](
streamingContext, [map of Kafka parameters], [set of topics to consume])
Word Count Example
For our example we are going to setup up a Kafka queue for reading messages directly prompted over the console. As a additional option to store the counts of words we will look into the use of HBase with Spark. Words in this demo will be counted for a certain interval demonstrating stateful window operations on created DStreams. The source code is available here.
Setup HBase
HBase an Kafka both rely on Zookeeper for coordination. While for Kafka we have to start Zookeeper separately with HBase standalone it comes embedded. Therefor we setup HBase first and than Kafka.
For quick start of Apache HBase we download a stable version (1.0.0), configure the hbase-site.xml accordingly, start the service, and create our sample database.
hbase-site.xml :
<configuration>
<property>
<name>hbase.rootdir</name>
<value>/tmp/hbase</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/tmp/zookeeper</value>
</property>
</configuration>
With this configuration in place we can start HBase and create the wanted database:
% bin/start-hbase.sh
% echo "create 'stream_count', {NAME => 'word'}" | hbase shell
Setup Kafka
After downloading Kafka we can create a simple topic for our purposes with the following:
# download and extract: http://kafka.apache.org/downloads.html % bin/kafka-server-start.sh config/server.properties % bin/kafka-topics.sh --create --topic sparktest --partition 1 --replication-factor 1 --zookeeper localhost:2181
Stream Count
Creating the SparkContext for the demo application is the same as for most other streaming application in Spark. Here a context is created with a batch interval of 2 Seconds:
val sparkConf = new SparkConf().setAppName("KafkaHBaseWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(2))
A simple Kafka DStream with receiver can be created with the following snippet. With the Kafka config we make the proper arrangements for the DStream to be able to read from the topic.
val kafkaConf = Map(
"metadata.broker.list" -> "localhost:9092",
"zookeeper.connect" -> "localhost:2181",
"group.id" -> "kafka-spark-streaming-example",
"zookeeper.connection.timeout.ms" -> "1000")
val lines = KafkaUtils.createStream[Array[Byte], String,
DefaultDecoder, StringDecoder](
ssc,
kafkaConf,
Map("sparktest" -> 1),
StorageLevel.MEMORY_ONLY_SER).map(_._2)
Message are read from Kafka as key (K) and values (V). In this example we don’t make any use of the key as of why a DefaultDecoder is used together with a Array[Byte] type. To be able to easily split the message into individual word we use a String type and StringDecoder for the value of the message.
As we know the receiver is a not very reliable part – depending on the design – of Spark Streaming and especially for Kafka. WAL, replication and checkpointing add an overhead to your application. Using the (yet experimental) direct stream connection will probably be the preferred setup for most use cases to come. Most other frameworks make good use of Zookeeper to store the current offset processed. In case of the the direct DStream implementation it keeps the within the RDD itself. Use rdd.asInstanceOf[HasOffsetRanges].offsetRanges for retrieving an array of current offsets to update vie Zookeeper manually, if needed.
val lines = KafkaUtils.createDirectStream[Array[Byte], String,
DefaultDecoder, StringDecoder](
ssc,
kafkaConf,
Set(topic)).map(_._2)
/* recieve offsets from the RDD */
lines.foreachRDD { rdd =>
val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
// ....
}
Windowing function in Spark provide a convenient way to operate on the distributed RDD in windowed intervals. Some operations that can be performed on DStreams in a stateful manner.
A list of stateful operations (Source of Table: http://spark.apache.org/docs/latest/streaming-programming-guide.html#window-operations):
| window(windowLength, slideInterval) | Return a new DStream which is computed based on windowed batches of the source DStream. |
| countByWindow(windowLength, slideInterval) | Return a sliding window count of elements in the stream. |
| reduceByWindow(func, windowLength, slideInterval) | Return a new single-element stream, created by aggregating elements in the stream over a sliding interval using func. The function should be associative so that it can be computed correctly in parallel. |
| reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks]) | When called on a DStream of (K, V) pairs, returns a new DStream of (K, V) pairs where the values for each key are aggregated using the given reduce function func over batches in a sliding window. Note: By default, this uses Spark’s default number of parallel tasks (2 for local mode, and in cluster mode the number is determined by the config property spark.default.parallelism) to do the grouping. You can pass an optional numTasks argument to set a different number of tasks. |
| reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks]) | A more efficient version of the above reduceByKeyAndWindow() where the reduce value of each window is calculated incrementally using the reduce values of the previous window. This is done by reducing the new data that enter the sliding window, and “inverse reducing” the old data that leave the window. An example would be that of “adding” and “subtracting” counts of keys as the window slides. However, it is applicable to only “invertible reduce functions”, that is, those reduce functions which have a corresponding “inverse reduce” function (taken as parameter invFunc. Like in reduceByKeyAndWindow, the number of reduce tasks is configurable through an optional argument. Note that [checkpointing](#checkpointing) must be enabled for using this operation. |
| countByValueAndWindow(windowLength, slideInterval, [numTasks]) | When called on a DStream of (K, V) pairs, returns a new DStream of (K, Long) pairs where the value of each key is its frequency within a sliding window. Like in reduceByKeyAndWindow, the number of reduce tasks is configurable through an optional argument. |
Windowing operations operate over a window duration and sliding duration. While the window duration controls how many previous batches are considered, does the sliding duration, which defaults to the batch interval, determine how often results are computed.
It’s possible to explicitly apply how elements from previous batches are added or removed to the computation. In our case it for addition _ + and deletion – _ . The graphic below tries to illustrate the windowing behavior in Spark Streaming.
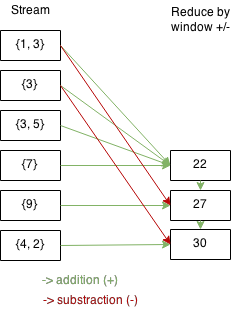 We use a local checkpoint folder and count the words every two seconds for 5 minutes:
We use a local checkpoint folder and count the words every two seconds for 5 minutes:
/* For stateful operations needed */
ssc.checkpoint("./checkpoints") // checkpointing dir
//ssc.checkpoint("hdfs://checkpoints") // dir in hdfs for prod
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1L))
.reduceByKeyAndWindow(_ + _, _ - _, Minutes(5), Seconds(2), 2)
wordCounts.print()
Alternatively storing the counts to HBase can be achieved by using TableOutputFormat with saveAsNewAPIHadoopFiles, as demonstrated below.
wordCounts.foreachRDD ( rdd => {
val conf = HBaseConfiguration.create()
conf.set(TableOutputFormat.OUTPUT_TABLE, "stream_count")
conf.set("hbase.zookeeper.quorum", "localhost:2181")
conf.set("hbase.master", "localhost:60000");
conf.set("hbase.rootdir", "file:///tmp/hbase")
val jobConf = new Configuration(conf)
jobConf.set("mapreduce.job.output.key.class", classOf[Text].getName)
jobConf.set("mapreduce.job.output.value.class", classOf[LongWritable].getName)
jobConf.set("mapreduce.outputformat.class", classOf[TableOutputFormat[Text]].getName)
rdd.saveAsNewAPIHadoopDataset(jobConf)
})
Running the demo:
% bin/spark-submit --master local[2] --class simpleexample.SparkKafkaExample target/spark-streaming-simple-example-0.1-SNAPSHOT.jar localhost:9092 localhost:2181 sparktest
Writing to the topic:
% bin/kafka-console-producer.sh --broker-list localhost:9092 --topic sparktest

Spark Streaming with Kafka & HBase Example http://t.co/ytNKXXo6ao
LikeLike
Hi Henning, running the code throws an exception :
“Error : application failed with exception org.apache.spark.SparkException : Job aborted due to stage failure: Task 0 in stage 2.0 times failed one , Most recent failure: Lost in stage task 0.0 2.0 ( TID 3 localhost ):java.lang.ClassCastException : java.lang .long can not be cast to org.apache.hadoop.hbase.client.Mutation ” …
Could you tell me any solution to run the code correctly,
Thanks.
Luis.
LikeLike
Hi Henning,
I also faced this exception. Any suggestions? Thanks!
Roland
LikeLike
Refer to https://github.com/hkropp/spark-streaming-simple-examples/blob/master/src/main/scala/simpleexample/SparkKafkaExample.scala
I’ve resolved this exception after refer to the sample above.
You can follow these following steps,
1. add convert funciton:
def convert(t: (String, Long)) = {
val p = new Put(Bytes.toBytes(t._1))
p.add(Bytes.toBytes(“word”), Bytes.toBytes(“count”), Bytes.toBytes(t._2))
(t._1, p)
}
2.call convert with map function:
rdd.map(convert).saveAsNewAPIHadoopDataset(jobConf)
instead of
rdd.saveAsNewAPIHadoopDataset(jobConf)
then all that you can go.
LikeLike