The developer API of Fitbit provides access to the data collected by it’s personal trackers for use with custom applications development. Besides read also write access can be used not only to it’s own but on behalf of other platform users via OAuth authentication. A comprehensive documentation of the Fitbit API can be found here: https://dev.fitbit.com/docs/ . Continue reading “Access to Fitbit API with Scala”
Month: March 2016
Automated Kerberos Install for HDP w/ Ambari + Puppet
With the release of Ambari 2.x kerberizing a HDP install improved quite a bit. Looking back at Kerberized Hadoop Cluster – A Sandbox Example compared to today most of the there described steps are much easier by now and can be automated. For long I was looking to include it into my existing Vagrant project for an end to end setup of a kerberized cluster. With the writing of this post I finally had the opportunity to do so.
In this post I would like to describe the parts added to the Vagrant setting needed to accomplish an end to end setup of a kerberized HDP cluster. Before the final step of the cluster setup by using the Ambari REST API, a KDC with credentials needs to be created. A Puppet module was created and included to achieve the installation of a MIT Kerberos install. Continue reading “Automated Kerberos Install for HDP w/ Ambari + Puppet”
10 Resources about Deep Learning & NLP
One approach to natural language processing that has gained tremendous traction recently is the vecotrization of words to represent their representation in a complex context. Deep Learning based sentiment analysis and general classifiers help improve the accuracy compared to results achieved with “classical” text analysis approaches. Tools like Word2Vec or GloVe are based on trained vectorized learning models that help in building commodity NLP available to a broad range of audience. Here is a list of resources to help you get started:
- Deep Learning for Natural Language Processing – Text By the Bay 2015 (Youtube)
- Deep Learning – Prof. Geoff Hinton (Youtube)
- Linguistic Regularities in Sparse and Explicit Word Representations (pdf)(slides)
-
Efficient Estimation of Word Representations in Vector Space – Tomas Mikolov, Kai Chen, Greg Corrado, Jeffrey Dean
- word2vec Explained: Deriving Mikolov et al.’s Negative-Sampling Word-Embedding Method, arXiv 2014. – Goldberg, Y., and Levy, O.
- GloVe: Global Vectors for Word Representation. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing
- A Word is Worth a Thousand Vectors. MultiThreaded, StitchFix, 11 March 2015. (Youtube)
- A Neural Network For Factoid Question Answering Over Paragraphs. Proceedings of EMNLP 2014 – Iyyer, M., Boyd-Graber, J., Claudino, L., Socher, R., and Daume III, H.
- Deep or Shallow, NLP is Breaking Out
- Deep Learning in a Nutshell (Part 1)(Part 2)(Part 3)
Plotting Graphs – Data Science with Scala
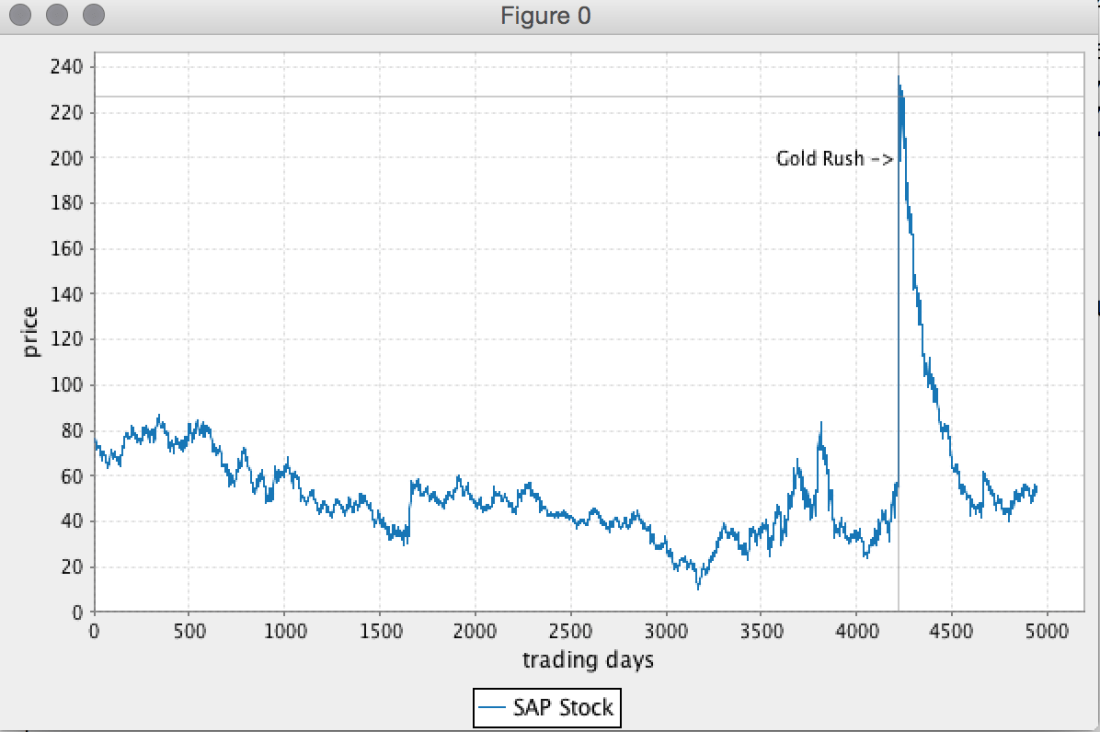
Data visualization is an integral part of data science. The programming language Scala has many characteristics that make it popular for data science use cases among other languages like R and Python. Immutable data structures and functional constructs are some of the features that make it so attractive to data scientists. Popular big data crunching frameworks like Spark or Flink do have their fair share on an ever growing ecosystem of tools and libraries for data analysis and engineering. Scala is particularly well suited to build robust libraries for scalable data analytics.
In this post we are going to introduce Breeze, a library for fast linear algebraic manipulation of data sets, together with tools for visualization and NLP. Starting with basic creation of vectors, we will create an application for plotting stock prices. The stock data is obtained form Yahoo Finance, but can also be downloaded here for SAP, YAHOO, BMW, and IBM. Continue reading “Plotting Graphs – Data Science with Scala”
