While at it’s core TensorFlow is a distributed computation framework besides the official HowTo there is little detailed documentation around the way TensorFlow deals with distributed learning. This post is an attempt to learn by example about TensorFlow’s distribution capabilities. Therefor the existing MNIST tutorial is taken and adapted into a distributed execution graph that can be executed on one or multiple nodes.
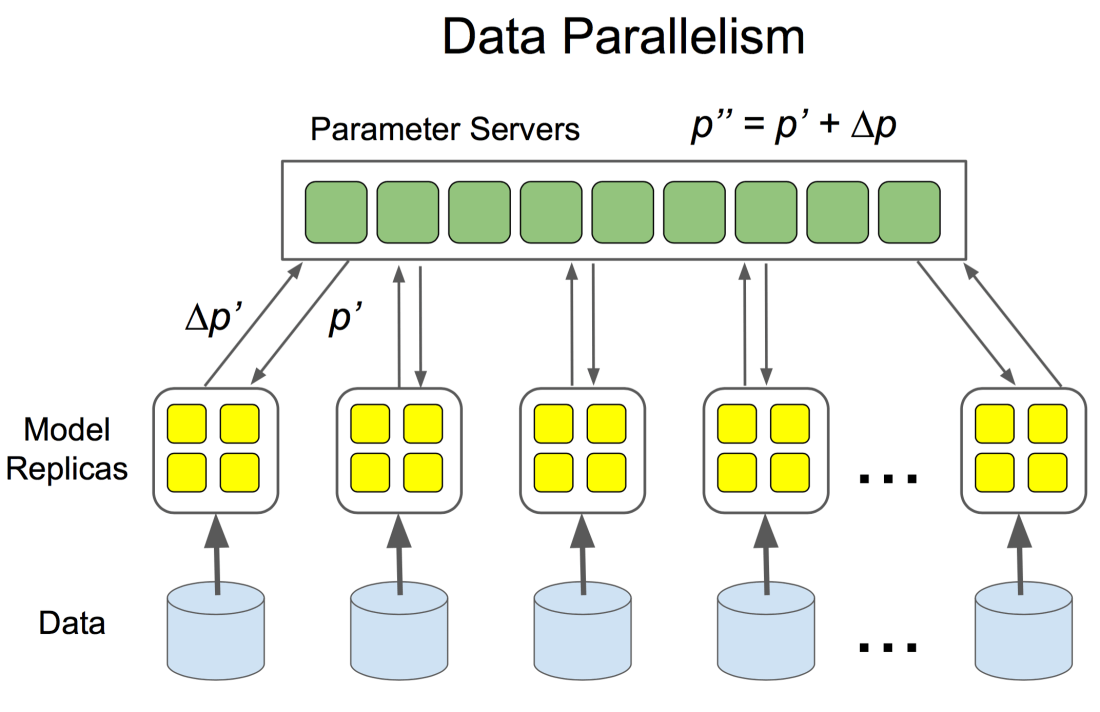
The framework offers two basic ways for distributed training of a model. In the simplest form the same data and computation graph is executed on multiple nodes in parallel on batches of the replicated data. This is known as Between-Graph Replication. Each worker updates the parameters of the same model, which means that each of the worker nodes are sharing a model. Updates to the shared model get averaged before being applied, this is at least the case for the synchronous training of a distributed model. In case of an asynchronous training the workers update the shared model parameters independently of each other. While the asynchronous training is known to be faster, the synchronous training proofs to provide more accuracy.
Continue reading “Distributing TensorFlow”
