Around 2009 the Stratosphere research project started at the TU Berlin which a few years later was set to become the Apache Flink project. Often compared with Apache Spark in addition to that Apache Flink offers pipelining (inter-operator parallism) to better suite incremental data processing making it more suitable for stream processing. In total the Stratosphere project aimed to provide the following contributions to Big Data processing. Most of it can be found in Flink today:
1 – High-level, declarative language for data analyisis
2 – “in suit” data analysis for external data sources3 – Richer set of primitives as MapReduce
4 – UDFs as first class citizens
5 – Query optimization
6 – Support for iterative processing
7 – Execution engine (Nephele) with external memory query processing
The Architecture of Stratosphere:
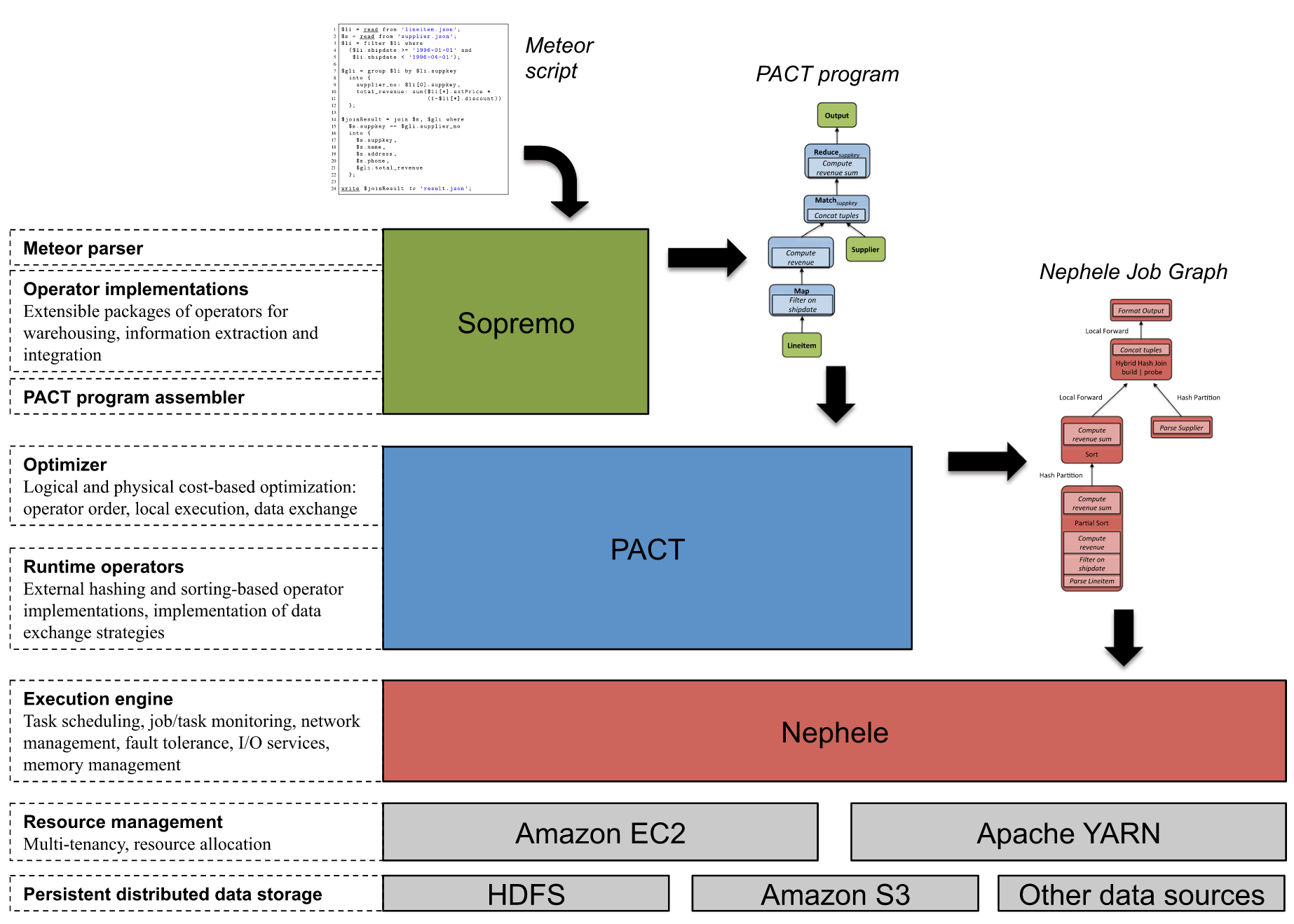
This posts contains 10 resource highlighting the building foundation of Apache Flink today. Continue reading “10 Resources for Deep Dive Into Apache Flink”
