Around 2009 the Stratosphere research project started at the TU Berlin which a few years later was set to become the Apache Flink project. Often compared with Apache Spark in addition to that Apache Flink offers pipelining (inter-operator parallism) to better suite incremental data processing making it more suitable for stream processing. In total the Stratosphere project aimed to provide the following contributions to Big Data processing. Most of it can be found in Flink today:
1 – High-level, declarative language for data analyisis
2 – “in suit” data analysis for external data sources3 – Richer set of primitives as MapReduce
4 – UDFs as first class citizens
5 – Query optimization
6 – Support for iterative processing
7 – Execution engine (Nephele) with external memory query processing
The Architecture of Stratosphere:
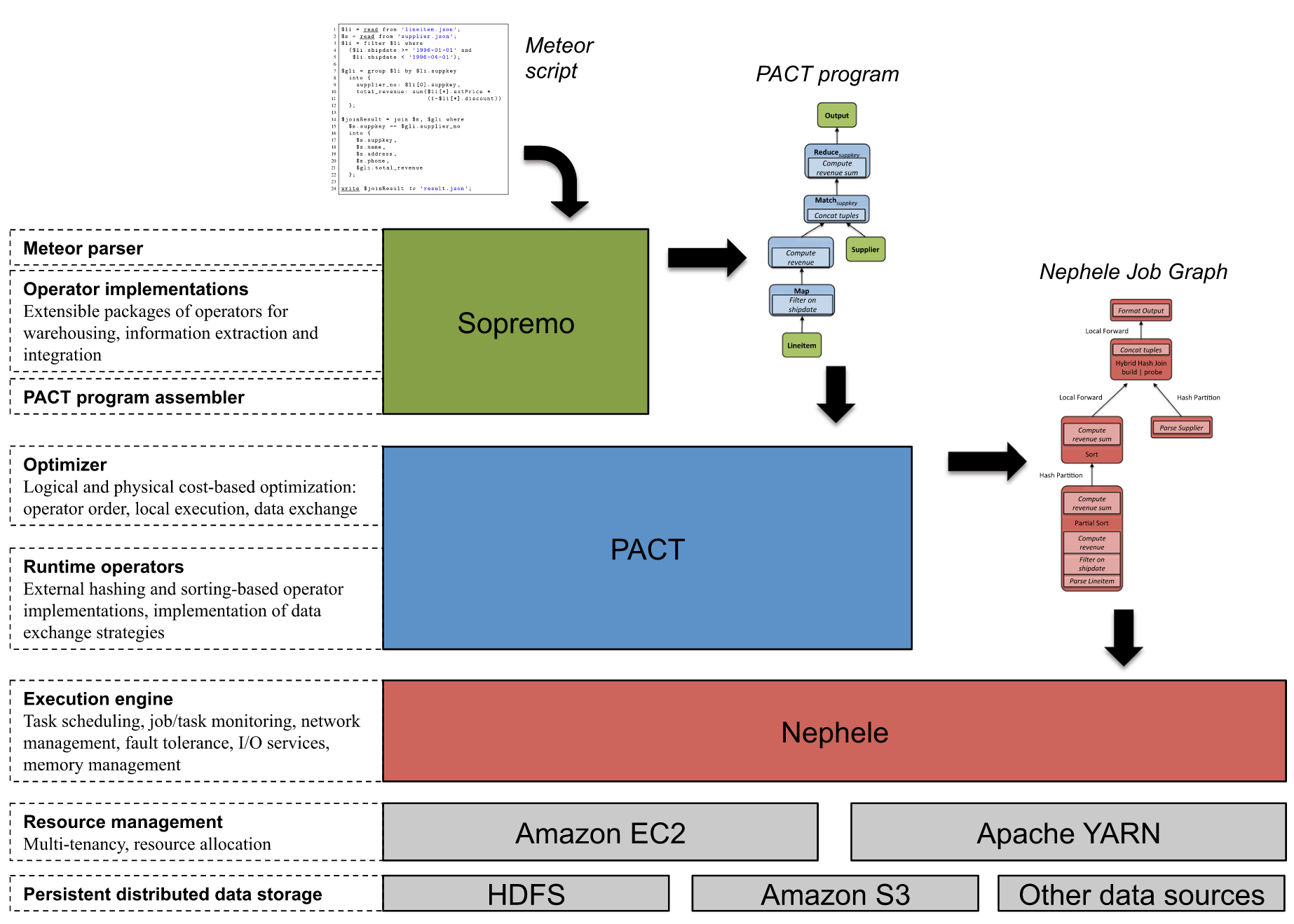
This posts contains 10 resource highlighting the building foundation of Apache Flink today.
- The Stratosphere platform for big data analytics
“The Spark system from UC Berkeley is a distributed system that operates on memory-resident data. Spark provides functionality equivalent to Stratosphere’s bulk iterations, but not incremental iterations. In addition, while Spark is a system that processes batches of data, Stratosphere features an execution engine that pipelines data. Pipelining is better suited to use cases that incrementally process data as found in many machine learning applications.”
- Iterative Parallel Data Processing with Stratosphere: An Inside Look
“In Stratosphere we distinguish between two different classes of iterative algorithms: bulk iterations and incremental iterations. Bulk iterations are the simple form of iterations: In each superstep, a bulk iteration evaluates the step function consuming the entire input (the result of the previous superstep, or the initial data set), and recomputes the next version of the intermediate solution.”
- Large-Scale Social-Media Analytics on Stratosphere
“In our demonstration, we highlight the exible and convenient support of PACTs to achieve this objective. We show how the Stratosphere system optimizes and executes the resulting programs in a massively parallel way and we emphasize the performance gains this provides.”
- Massively-Parallel Stream Processing under QoS Constraints with Nephele
- Optimistic Recovery for Iterative Dataflows in Action
- Meteor/Sopremo: An Extensible Query Language and Operator Model
- PAXQuery: Parallel Analytical XML Processing
“PAXQuery compiles a rich subset of XQuery into plans expressed in the PArallelization ConTracts (PACT) programming model. Thanks to this translation, the resulting plans are optimized and executed in a massively parallel fashion by the Apache Flink system.”
- “All Roads Lead to Rome:” Optimistic Recovery for Distributed Iterative Data Processing
“We propose a novel optimistic recovery mechanism that does not checkpoint any state. Therefore, it provides optimal failure-free performance and simultaneously uses less resources in the cluster than traditional approaches.”
- Flink Forward: Conference Around Apache Flink
- Quick Start: Setup
