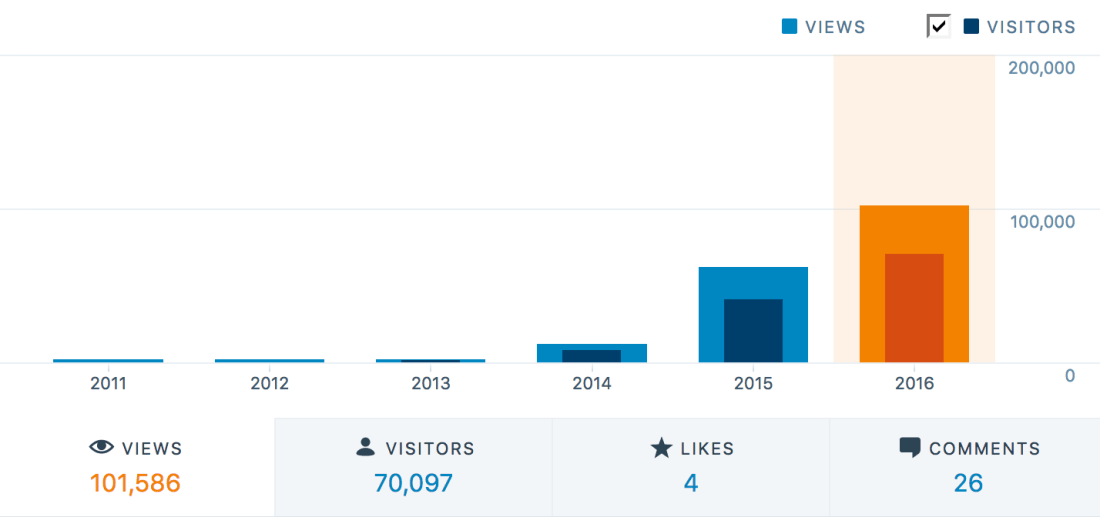
Over two years ago in March 2014 I joined the Iron Blogger community in Munich, which is one of the largest, still active Iron Blogger communities worldwide. You can read more about my motivation behind it here in one of the 97 blog posts published to date: Iron Blogger: In for a Perfect Game.
The real fact is that I write blogs solely for myself. It’s my own technical reference I turn to. Additionally writing is a good way to improve once skills and technical capabilities, as Richard Guindon puts it in his famous quote:
“Writing is nature’s way of letting you know how sloppy your thinking is.”
What could be better suited to improve something than by leaning into the pain, how the great Aaron Swartz, who died way too early, once described it? And it is quite a bit of leaning into the pain publishing a blog post every week. Not only for me, but also for those close to me. But I am going to dedicate a separate blog post to a diligent retrospection in the near future. This post should all be about NUMBERS. Continue reading “2016 in Numbers”