Over two years ago in March 2014 I joined the Iron Blogger community in Munich, which is one of the largest, still active Iron Blogger communities worldwide. You can read more about my motivation behind it here in one of the 97 blog posts published to date: Iron Blogger: In for a Perfect Game.
The real fact is that I write blogs solely for myself. It’s my own technical reference I turn to. Additionally writing is a good way to improve once skills and technical capabilities, as Richard Guindon puts it in his famous quote:
“Writing is nature’s way of letting you know how sloppy your thinking is.”
What could be better suited to improve something than by leaning into the pain, how the great Aaron Swartz, who died way too early, once described it? And it is quite a bit of leaning into the pain publishing a blog post every week. Not only for me, but also for those close to me. But I am going to dedicate a separate blog post to a diligent retrospection in the near future. This post should all be about NUMBERS.
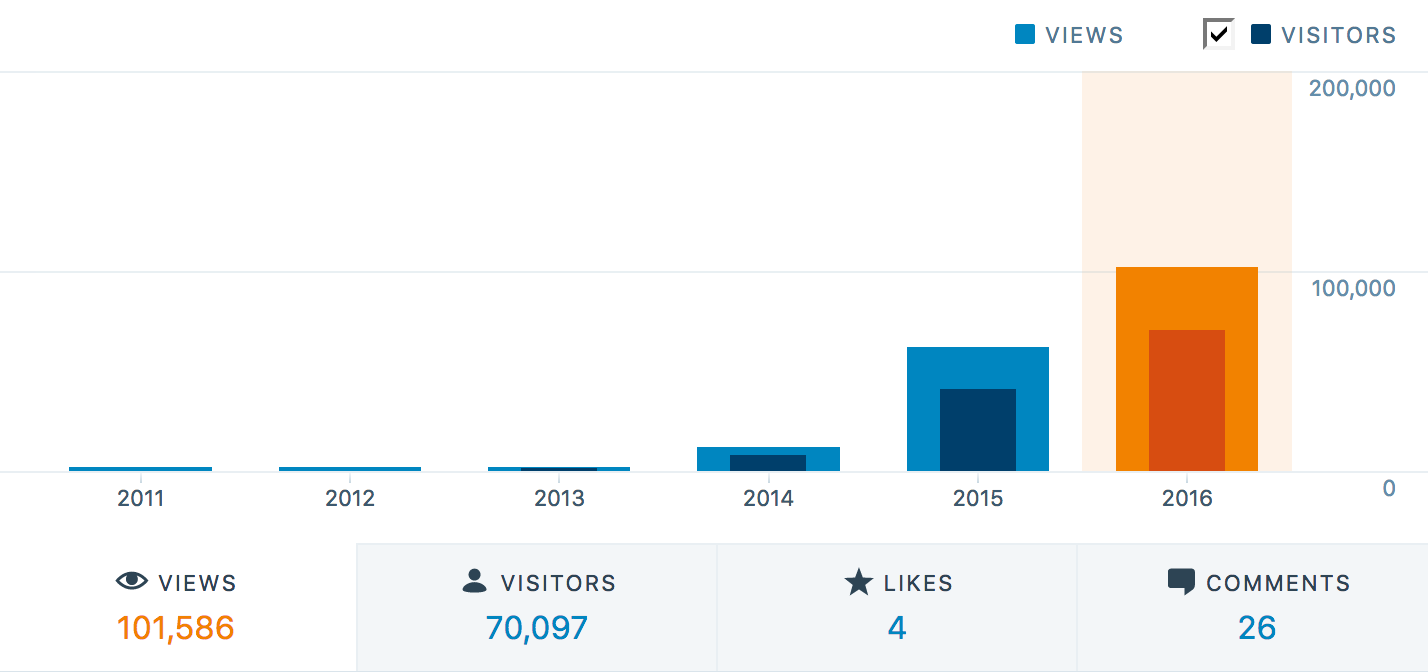
Closing 2016 now with over 70,000 visitors with more than 100,000 views it becomes apparent that others out there seem to find some value in my writing. While views and visitors metrics look quite impressive, I am more appreciative for the 26 comments and the numerous Stack Overflow reference that demonstrate active engagement with my writing for which I am very grateful.
How many @StackOverflow references are required until one gets its own Stack Exchange Community? 😉 #askingforafriend pic.twitter.com/0wZhroHk2h
— Henning Kropp (@jonbros) 25. Oktober 2016
//platform.twitter.com/widgets.js
Zeppelin for Rapid Data Discovery
By divining into the numbers provided by the Jetpack plugin of WordPress.com with Apache Zeppelin it shows how simple rapid data discovery has become for Big Data using Apache Spark. For those interested in playing around with the data for themselves I here provide them for download:
- posts.xml
- posts_year_2016.csv
- searchterms_year_2016.csv
- countries-summary_year_2016.csv
- clicks_year_2016.csv
- referrers_year_2016.csv
Visitors and Views
Unfortunately the Jetpack statistics don’t provide the overview numbers for download, or at least I didn’t find them. But they are simple enough to type them into a custom sequence for Spark.
%spark
case class WPVisit( year: String, views: Int, visitors: Int, likes: Int, comments: Int)
val wpVisits = Seq(
WPVisit("2011", 1, 0, 0, 0),
WPVisit("2012", 99, 10, 0, 0),
WPVisit("2013", 1501, 994, 0, 0),
WPVisit("2014", 10690, 7363, 0, 14),
WPVisit("2015", 60851, 40358, 0, 23),
WPVisit("2016", 101583, 70097, 4, 26)
)
val wpVisitsDf = sc.parallelize(wpVisits).toDF
wpVisitsDf.registerTempTable("wp_visits")
sqlContext.cacheTable("wp_visits")
In order to use them with SparkSQL we provide a schema to a Dataframe overlay of the RDD via Scala case class. The Dataframe of WordPress visits gets registered as a temporary table and we cache it for quick queries.
At first we are interested in the overall visitors of the blog:

Visits before 2013 are fairly marginal and we might achieve a more comprehensive visualization by filtering out the years before 2013. The year is a string that can be used for range filtering as follows:

As you can see the visitors are growing significantly at least in total numbers, but how does this compare to the year over year growth in percentage. We can use the window function of SparkSQL over the visitors and views over the previous year.
Our HiveContext in this case will fail with:
Window function LEAD does not take a frame specification.
because the window frame definition is not supported.
We can use the SparkSQL windows function with LAG of one to get the visitors and views growth compared to the previous year. Again we register it as a temporary table and cache it:
%spark
import org.apache.spark.sql.expressions.Window
val windowSpec = Window.orderBy("year")
wpVisitsDf
.withColumn("visit_delta", wpVisitsDf("visitors") - (lag("visitors", 1, 0) over windowSpec) )
.withColumn("visit_delta_pc",
(wpVisitsDf("visitors") - (lag("visitors", 1, 0) over windowSpec) ) /
wpVisitsDf("visitors") * 100
)
.withColumn("view_delta", wpVisitsDf("views") - (lag("views", 1, 0) over windowSpec) )
.withColumn("view_delta_pc",
(wpVisitsDf("views") - (lag("views", 1, 0) over windowSpec) ) /
wpVisitsDf("views") * 100
)
.registerTempTable("wp_visits2")
sqlContext.cacheTable("wp_visits2")
From the result we can see that the growth has slowed down most likely due to the effect of small numbers at the beginning. The ratio of views and visitors is rather constant:

Further investigation into the ratio of views and visitors does support the observation of a stable ratio between views and visits around 1.5 page views per visitor:

As I mentioned previously the most appreciation do I get from active feedback in form of comments. So how did the ratio of comments per visitor develop over last 3 years?

In one picture:

Most Frequent Post
Let’s continue with some insides around what were the most common posts read during 2016. For this we need the posts_year_2016.csv containing the post view metrics by Jetpack.
%spark
case class WPPost(title: String, views: Int)
val WPPostsRdd = sc.textFile("posts_year_2016.csv")
val WPPostsDf = WPPostsRdd.map( _.split(",") ).map( x => WPPost( x(0).replace(""", ""), x(1).toInt ) ).toDF
WPPostsDf.registerTempTable("wp_posts")
sqlContext.cacheTable("wp_posts")
Here are the Top 10:

Again we use a window function this time to calculate the rank of the posts in descending order of the views count. The most obvious reason to do so, is that it looks much better when we plot the distribution as a bar chart 🙂

But what does the distribution look like, if we look at all the articles of 2016?

With out great surprise the distribution is highly left skewed. It is almost as if you can see the 80/20 (Pareto principal) rule already from the graph above. Meaning that 20% of the articles are responsible for 80% of the traffic. Why do I even bother writing the other 80%? 😉 I should only write 20% of my posts ….
But can we prove the 80/20 rule here? Lets try with n-tiles:

This is a perfectly fine Pareto principal distribution. Our first ntile out of 5 (20%) accounts for 78,223 view out of 101,583 so 77.004%.

Hot Topics
What were the hottest topics of the year 2016 on my blog? To answer this questions we need additional information to the posts, that the Jetpack plugin does not provide.
Therefor we take a dump of the published blog post from the blog itself and combine it with the view stats of Jetpack.
WordPress provides post dumps in XML format that is why are using the XML package of Databricks provided here: https://github.com/databricks/spark-xml
Adding this to Zeppelin can be achieved in the interpreter section under Spark, where we already have the Kafka Streaming packages for our previous Kafka + Spark Streaming demo.

With the Spark XML package we are able to directly load the post dump of WordPress as a table into our context using SparkSQL for querying:
%sql CREATE TABLE IF NOT EXISTS posts (title string, link string, pubDate string, category array<string>, `wp:post_date` string) USING com.databricks.spark.xml OPTIONS (path "posts.xml", rowTag "item")
We can now join this table together with our views stats CSV file and use the category information to compare views by category. We here compare the categories HIVE, SPARK, STORM, and HADOOP SECURITY with the rest of the posts:
%sql
SELECT t.post_type, SUM(t.views) as views, COUNT(*) as cnt, AVG(t.views) as avg FROM (
SELECT p.title, wp.views,
(CASE
WHEN (ARRAY_CONTAINS(p.category, "Storm")) THEN "storm"
WHEN (ARRAY_CONTAINS(p.category, "Spark")) THEN "spark"
WHEN (ARRAY_CONTAINS(p.category, "Hive")) THEN "hive"
WHEN (ARRAY_CONTAINS(p.category, "Hadoop Security")) THEN "security"
ELSE "all"
END) AS post_type
FROM posts AS p
JOIN wp_posts AS wp ON p.title = wp.title
--WHERE ARRAY_CONTAINS(p.category, "Storm") OR ARRAY_CONTAINS(p.category, "Spark")
) AS t
GROUP BY t.post_type
ORDER BY avg DESC
Which gives us in AVERAGE:

And in TOTAL VIEWS:

This concludes my blogging year 2016 presented here in numbers taken form visitor statistics of my blog. I am looking forward to another great year of blogging in 2017. I am very very grateful for everyone taking interest in my writings.
Further Reading
- HAPPY NEW YEAR 2017!
