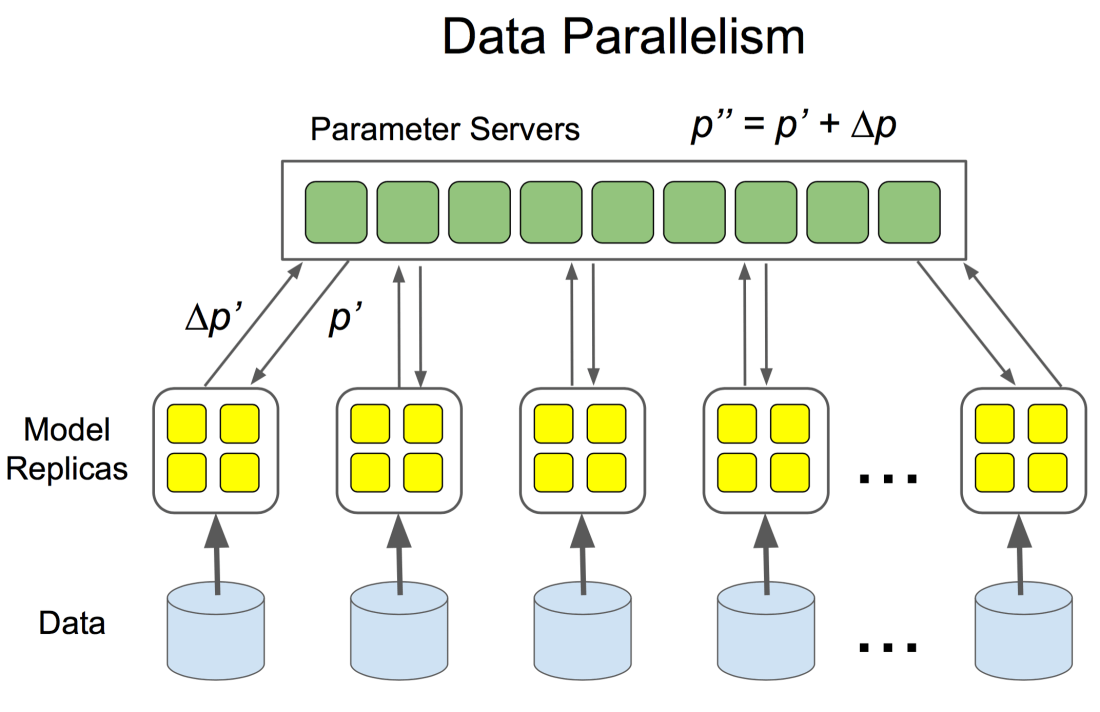
If you look at the way TensorFlow distributes it’s calculation across a cluster of processes, you will quickly ask how to schedule resources as part of a training workflow on large scale infrastructure. Many have turned to Spark as a resource manager for TrndorFlow, At the beginning quite a lot of folks have answered this question by wrapping an additional computational framework around TensorFlow, degrading the former to a distribution framework. Examples of such approaches can be found here and here. Both of them turn to Spark, which just like TensorFlow, is a computational distributed framework turning a set of statements into a DAG of execution. While this certainly would works a more straight forward approach would be to turn to a cluster managers like Mesos, Kubernetes, or namely YARN to distribute the workloads of a DeepLearning networking. Such an approach is also the suggested solution you would find in the TensorFlow documentation:
Note: Manually specifying these cluster specifications can be tedious, especially for large clusters. We are working on tools for launching tasks programmatically, e.g. using a cluster manager like Kubernetes. If there are particular cluster managers for which you’d like to see support, please raise a GitHub issue.