Streamline data processing has become an inherent part of a modern data architecture build on top of Hadoop. Big Data applications need to act on data being ingested at a high rate and volume in real time. Sensor data, logs and other events likely have the most value when being analyst at the time they are emited – in real time.
For over 6 years Apache Storm has matured at hundreds of global companies to the preferred stream processing engine on top of Hadoop. In a more recent approach Spark Streaming was published build around Spark‘s Resilient Distributed Datasets (RDD). Constructed with the same concepts as Spark, a in-memory batch compute enginge, Spark Streaming is offering the clear advantage of bringing batch and real time processing closer together, as ideally the same code base can be leveraged for both.
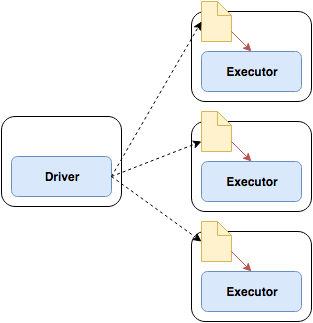
Hence Spark Streaming is a so called micro-batching framework that uses timed intervals. It uses so called D-Streams (Discretized Stream) that structure computation as small sets of short, stateless, and deterministic tasks. State is distributed and stored in fault-tolerant RDDs. A D-Stream can be build from various data sources as Kafka, Flume, or HDFS offering many of the same operations available for RDDs with additional operations typical for time operations such as sliding windows.
In this post we are looking at a fairly basic example of using Spark Streaming. We will listen to a server emitting line by line in this example. Continue reading “Spark Streaming – A Simple Example” →