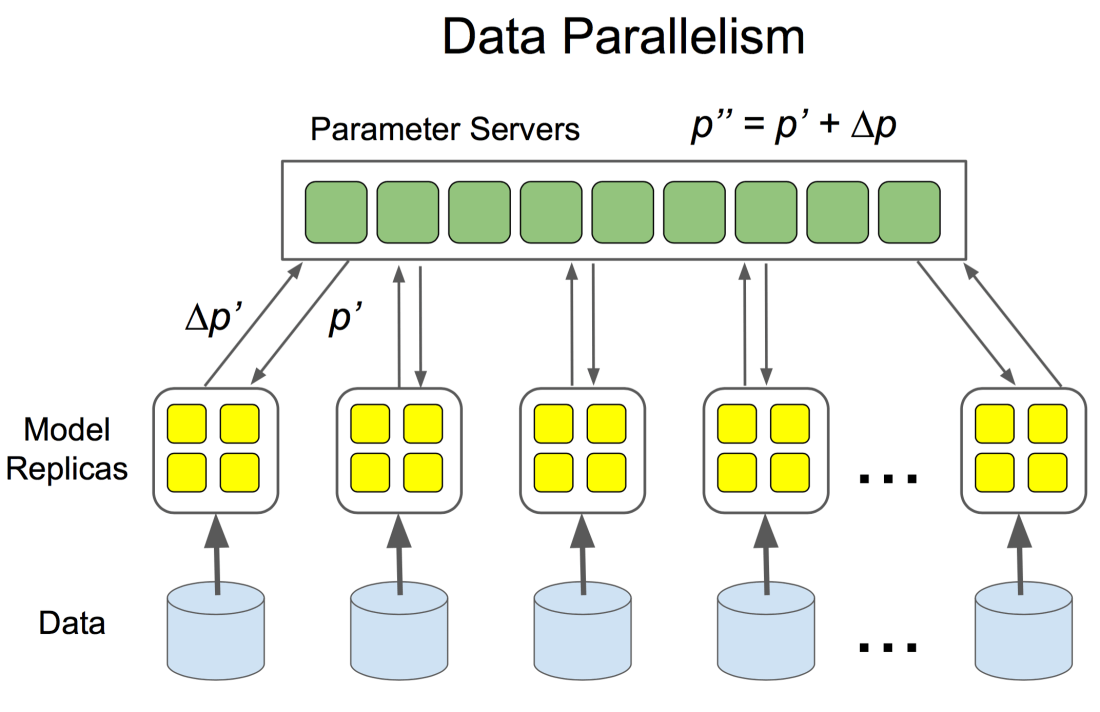
Some collection of papers and work around deep distributed learning to deepen once understanding in that topic:
Large Scale Distributed Deep Networks (link) (December, 2012)
Jeffrey Dean, Greg S. Corrado, Rajat Monga, Kai Chen, Matthieu Devin, Quoc V. Le, Mark Z. Mao, Marc’Aurelio Ranzato, Andrew Senior, Paul Tucker, Ke Yang, Andrew Y. Ng
This paper published, among other contributes, by Jeffrey Dean together with Andrew NG probably marks the cornerstone to TensorFlow as it is today.
[PDF]
Efficient Estimation of Word Representations in Vector Space (link) (Januar 2013)
Tomas Mikolov, Kai Chen, Greg Corrado, Jeffrey Dean
The fundamental work around projects like Word2Vec is presented in this paper, where vector representation of words for similarity trained by a neural net is being described.
[PDF]
Sequence to Sequence Learning with Neural Networks (link) (September 2014)
Ilya Sutskever, Oriol Vinyals, Quoc V. Le
The work around sequence to sequence learning is actually quite old. Which seems like a fairly abstract problem to solve has recently proved to significantly improve for example speech to text recognition among other disciplines.
[PDF]
Show and Tell: A Neural Image Caption Generator (link) (November 2014)
Oriol Vinyals, Alexander Toshev, Samy Bengio, Dumitru Erhan
Another area were the above described concept of sequence to sequence learning is described is the exploration of images. In this case the input sequence is a bitmap of an image which is transferred to a text sequence describing the image. This marks a fundamental breakthrough in computer AI.
TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems (link) (November 2015)
Martín Abadi, Ashish Agarwal, Paul Barham, Eugene Brevdo, Zhifeng Chen, Craig Citro, Greg S. Corrado, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Ian Goodfellow, Andrew Harp, Geoffrey Irving, Michael Isard, Rafal Jozefowicz, Yangqing Jia, Lukasz Kaiser, Manjunath Kudlur, Josh Levenberg, Dan Mané, Mike Schuster, Rajat Monga, Sherry Moore, Derek Murray, Chris Olah, Jonathon Shlens, Benoit Steiner, Ilya Sutskever, Kunal Talwar, Paul Tucker, Vincent Vanhoucke, Vijay Vasudevan, Fernanda Viégas, Oriol Vinyals, Pete Warden, Martin Wattenberg, Martin Wicke, Yuan Yu, and Xiaoqiang Zheng
The TensorFlow Whitepaper [PDF]
Webinar: TensorFlow: A Framework for Scalable Machine Learning (link) (October 19, 2016)
Martin Wicke, Software Engineer at Google
Rajat Monga, Engineering Director at Google
Martin and Rajat, both software engineers for Google working on TensorFlow, walk through the architecture and design of TensorFlow throughout this webinar.