Streamline data processing has become an inherent part of a modern data architecture build on top of Hadoop. Big Data applications need to act on data being ingested at a high rate and volume in real time. Sensor data, logs and other events likely have the most value when being analyst at the time they are emited – in real time.
For over 6 years Apache Storm has matured at hundreds of global companies to the preferred stream processing engine on top of Hadoop. In a more recent approach Spark Streaming was published build around Spark‘s Resilient Distributed Datasets (RDD). Constructed with the same concepts as Spark, a in-memory batch compute enginge, Spark Streaming is offering the clear advantage of bringing batch and real time processing closer together, as ideally the same code base can be leveraged for both.
Hence Spark Streaming is a so called micro-batching framework that uses timed intervals. It uses so called D-Streams (Discretized Stream) that structure computation as small sets of short, stateless, and deterministic tasks. State is distributed and stored in fault-tolerant RDDs. A D-Stream can be build from various data sources as Kafka, Flume, or HDFS offering many of the same operations available for RDDs with additional operations typical for time operations such as sliding windows.
In this post we are looking at a fairly basic example of using Spark Streaming. We will listen to a server emitting line by line in this example.
Setting up the Project
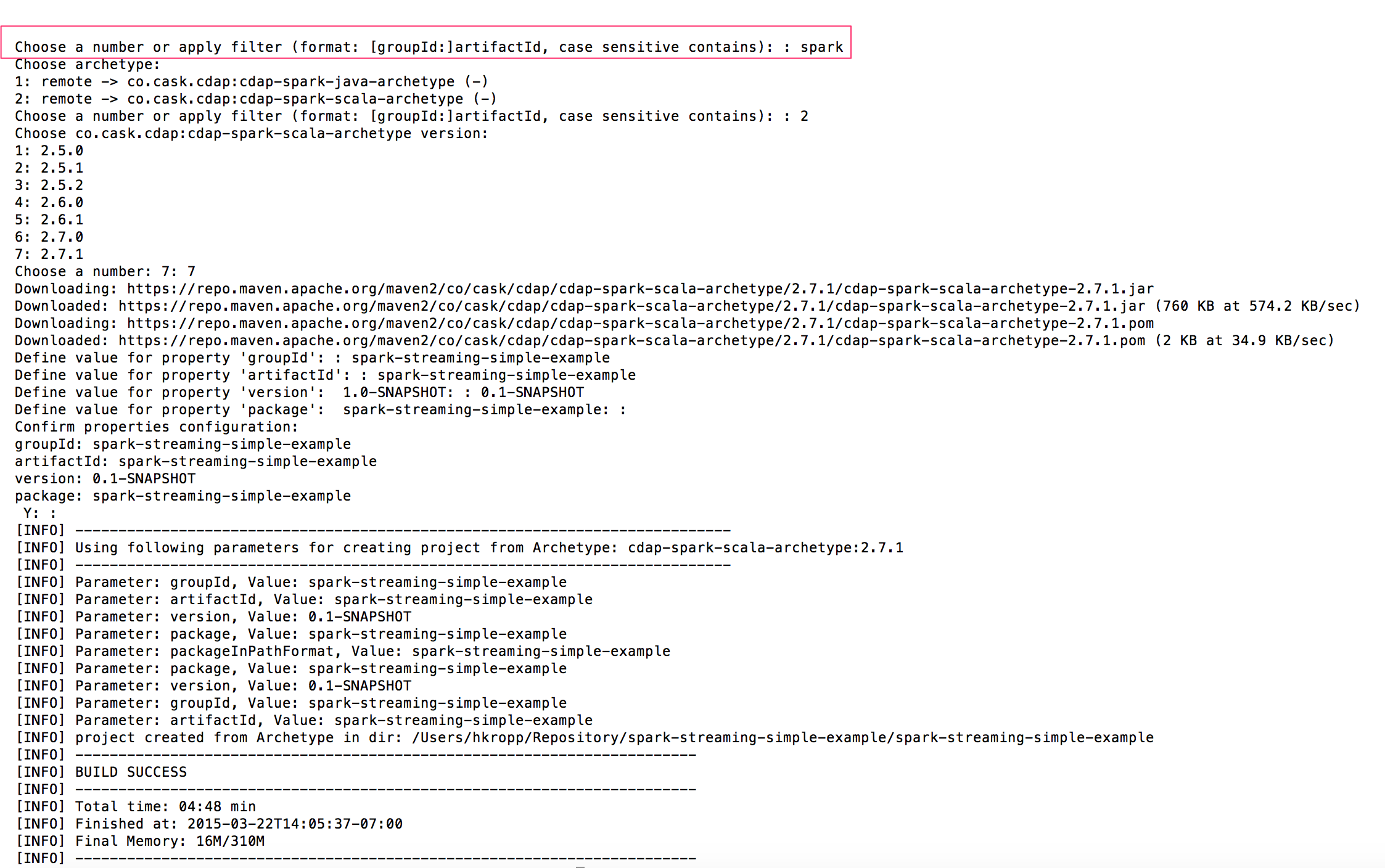
Quickly setting up a Spark or Scala project can be achieved by using Maven archtypes as explained in detail here. Cask Data makes a spark artifact available that can be used to quickly bootstrap a spark project.
$ mvn archetype:generate ... filter by "spark" ... name artifactId, groupId, and Version ... adjust pom
To use the Cask Data archtype:
 Make sure in the pom to adjust the following to make use of Spark 1.3 which is the current stable release of Spark. Also include the spark-streaming_2.10 for streaming.
Make sure in the pom to adjust the following to make use of Spark 1.3 which is the current stable release of Spark. Also include the spark-streaming_2.10 for streaming.
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>1.3.0</version>
<scope>provided</scope>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.10</artifactId>
<version>1.3.0</version>
<scope>provided</scope>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
NetworkWordCount
The NetworkWordCount example used here first sets up a local StreamContext that uses a 1 second batch interval.
// Create a local StreamingContext with two working thread and batch interval of 1 second.
// The master requires 2 cores to prevent from a starvation scenario.
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(1))
With this context in place we can create a D-Stream that listens to the host and port we provide as command arguments to the application:
if (args.length < 2) {
System.err.println("Usage: NetworkWordCount <hostname> <port>")
System.exit(1)
}
// Create a DStream that will connect to hostname:port
val lines = ssc.socketTextStream(args(0), args(1).toInt, StorageLevel.MEMORY_AND_DISK_SER))
With we allow Spark to persist RDDs to disk as well. Go here to find out more about Spark storage levels and which to choose.
By now we have a socket stream established based in a Spark context on top of D-Streams that reads line by line, every second. Next we would want to actually transform this stream into a bag of words aggregating it into a list of word counts. To transform the lines emitted by the stream into a set of words we would split it up like the following:
// Split each line into words
val words = lines.flatMap(_.split(" "))
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
// Print the first ten elements of each RDD generated in this DStream to the console
wordCounts.print()
Our list of word counts are created by reducing set of words over each by then read RDD. At the end we print out that result.
To actually run the context we would finally start the context until we receive a termination.
ssc.start() // Start the computation ssc.awaitTermination() // Wait for the computation to terminate
Building and Running the Example
Spark applications can be run best locally using it as a Standalone Application. Therefor one of the quickest way to run the example would be by building Spark locally. First we would need to checkout the source via github. Examples of building Spark can be found here. Running it all together:
$ git clone git@github.com:/apache/spark $ cd spark/ $ export MAVEN_OPTS="-Xmx2048m -XX:MaxPermSize=512m" // ensuring enough perm mem $ mvn -Pyarn -Phive -Dhadoop.version=2.6.0 -DskipTests clean package
Now we can submit our example.
$ cd spark $ ./bin/spark-submit --master local[2] --class simpleexample.SparkStreamingExample spark-streaming-simple-example-0.1-SNAPSHOT.jar localhost 9999
Running the socket server for testing:
$ nc -lk 9999 hello world hello world hello spark ....

Please stop use wordcount examples ! There many other good use cases you can take as an example. Which will give more in depth knowledge on concept.
LikeLike