Apache Kafka is a distributed system designed for streams that is often being categorized as a messaging system but provides a fundamentally different abstraction, although it serves a similar role. The key abstraction of Kafka to keep in mind is a structured commit log of events. With events being any kind of system, user, or machine emitted data. Kafka is built to:
- Fault-tolerant
- High throughput
- Horizontally scalable
- Allow geographically distributing data streams and processing.
A constantly growing number of data generated at today companies is event data. While there is an approach to combine machine generated data under the umbrella term of
Internet-of-Things (IoT) it is crucial to understand that business is inherently event driven.
A purchase, a customer claim or registration are just examples of such events. Business is interactive. When analyzing the data time matters. Most of this data has it’s highest value when analyzed close to or even in real-time.
Apache Kafka was created to solve two main problems that arise from the ever increasing demand for stream data processing. Designed for reliability Kafka is capable of scaling against the growing demand for events passing. Secondly Kafka can interact with various applications and platform for the same events, which helps to orchestrated today’s complex architectures providing a central message hub for each system. Today chances are that all that data will end up in Hadoop for further or even real time analyses making Kafka a queue to Hadoop.
Kafka Design
In summary Kafka is build around 4 design principals that make it very attractive:
- Low Overhead for Network and Storage
- High Throughput and Low Latency
- Distributed and Highly Scalable
- Simple API
Essentially Kafka can be described as a distributed commit log, but more commonly people would refer to Kafka as being a message queue. As a publish-subscribe system it uses a Push-Pull model to make messages available in the order they arrive. Message queues are so called topics to which producers publish events. Consumers pull topics to receive the emitted events. Both consumer and producer connect to a broker that is holding the topic.

An offset is assigned to each message that arrives at the topic in an ascending order. This preserves the overall order of messages within a topic. Consumers pull events in the same order from the topic by keeping track of the offset. This solves some important problems for a central messaging system. The Kafka broker takes no care of what event is severed to what consumer. It is up to the consumer to keep track of the current position and it’s order.
This way Kafka can with almost no overhead support an arbitrary number of consumers that can be at different offset of the same queue. This also allows for consumers to compute an event again if for example it finds out that the computation of the event the first time was not successful (replay capability), because Kafka persists all messages to disk.
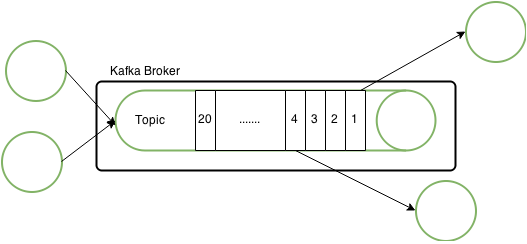
Kafka is highly scalable. The first thing to note is that a Kafka broker typically runs on
one node holding multiple topics. Adding additional nodes (brokers) to Kafka does not require a special broker in the sense of a master/slave concept. All brokers are equal. Kafka heavily relies on Zookeeper for it’s distribution. Brokers in the same cluster share the same Zookeeper cluster.
Topics in Kafka are scaled by partitioning. The number of partitions determine the number of parallelism you can achieve. Within one application there is typically one Consumer per partition to read from Kafka. In Storm for example having a lower number of parallelism for a Kafka spout leads to messages not being processed, while having a higher number leaves those threads idle.
Although messages are persist to disk to achieve fail-over partitions can be replicated across different nodes. When replicated a replicated partition is placed on a broker on a different node. One of the brokers acts as the lead for that partitions. Messages are send successfully when written to both partitions. The reliability is configurable as this obviously introduces some overhead.

With partitioning Kafka topics can easily be scaled to the desired throughput and latency.
But with partitions a total order of events over the topic can no longer be guaranteed. The
order by partition can still be preserved. This might in some cases not be enough. For this Kafka has the possibility to assign keys to partitions. Events with the same key would always got to the same partition. That way an order of events within a topic can at least be guaranteed.

With replication enabled the number of nodes a Kafka cluster can tolerate to fail can be calculated by the number of brokers minus the replication factor. Keep in mind that a messages needs to be written to the partition and the number of replicas to be successful. So in the above case a failure of one node can’t be tolerated.
#_of_brokers - replication_facter = #_of_node_failure
Kafka Quick Examples
It is easy to quickly try out Kafka, if for example you have a running HDP sanbox to run the following commands:
- Create topic
/usr/hdp/2.2.0.0-2041/kafka/bin/kafka-topics.sh --zookeeper localhost:2181 --create --topic test_topic --partitions 2 --replication-factor 1
- Create producer
With this simple producer you can emit a message to the topic with writing to the prompt and hitting enter.
/usr/hdp/2.2.0.0-2041/kafka/bin/kafka-console-producer.sh --broker-list sandbox.com:6667 --topic test_topic
- Create consumer
With a consumer per partition you can now listen in to the stream of events.
/usr/hdp/2.2.0.0-2041/kafka/bin/kafka-simple-consumer-shell.sh --broker-list sandbox.com:6667 --topic test_topic --partition 0
- Make Offset Visible in Consmer
/usr/hdp/2.2.0.0-2041/kafka/bin/kafka-simple-consumer-shell.sh --broker-list sandbox.com:6667 --topic test_topic --partition 0 --print-offsets

One thought on “Apache Kafka: Queuing for Hadoop”