Working with complex data events can be a challenge designing Storm topologies for real-time data processing. In such cases emitting single values for multiple and varying event characteristics soon reveals it’s limitations. For message serialization Storm leverages the Kryo serialization framework used by many other projects. Kryo keeps a registry of serializers being used for corresponding Class types. Mappings in that registry can be overridden or added making the framework extendable to diverse type serializations.
On the other hand Avro is a very popular “data serialization system” that bridges between many different programming languages and tools. While the fact that data objects can be described in JSON makes it really easy to use, Avro is often being used for it’s support of schema evolution. With support for schema evolution the same implementation (Storm topology) could be capable of reading different versions of the same data event without adaptation. This makes it a very good fit for Storm as a intermediator between data ingestion points and data storage in today’s Enterprise Data Architectures.

The example here does not provide complex event samples to illustrated that point, but it gives an end to end implementation of a Storm topology where events get send to a Kafka queue as Avro objects processesed natively by a real-time processing topology. The example can be found here. It’s a simple Hive Streaming example where stock events are read from a CSV file and send to Kafka. Stock events are a flat, none complex data type as already mentioned, but we’ll still use it to demo serialization with using Avro.
Deserialization in Storm
Before we look at the beginning, let’s start with the end. When we have everything working properly we should be able to use our defined event object as such in any bolt part of the topology:
Stock stock = (Stock) tuple.getValueByField("myobj_fieldname");
// OR by index //
Stock stock = tuple.getValue(0);
As demonstrated we should be able to cast our object simply from the tuple as it will already be present in serialized form inside the tuple. Storm will take care of the serialization for us. Remember Storm internally is using Kryo for Serialization as described here. It is using this for all data types in a tuple. To make this work with our object described in Avro we simply have to register a customer serializer with Storm’s Kryo.
The above snippet also concludes, that if we try to get retrieve the date in any other way, for example like this tuple.getBinary(0) we will receive an error. An Exception in such a case could look like this:
2015-09-23 10:52:57 s.AvroStockDataBolt [ERROR] java.lang.ClassCastException: storm_hive_streaming_example.model.Stock cannot be cast to [B
java.lang.ClassCastException: storm_hive_streaming_example.model.Stock cannot be cast to [B
at backtype.storm.tuple.TupleImpl.getBinary(TupleImpl.java:144) ~[storm-core-0.10.0.2.3.0.0-2557.jar:0.10.0.2.3.0.0-2557]
at storm_hive_streaming_example.FieldEmitBolt.execute(FieldEmitBolt.java:34) ~[stormjar.jar:na]
The sample error message clearly stats that our already serialized object simply can not be cast to a binary.
So how do we set things up from the start?
Spout Scheme
Let’s return to the beginning of all, the ingestion of events into a queue for example. The part being responsible for reading an event of a data source, like for example a message broker, is known as a Spout to Storm. Typically we have one spout for a specific data source other than having single purpose Spouts of a topology. Hence the a spout needs to be adaptive to the use case and events being issued. Storm uses so called “Scheme” to configure the data declaration of receiving and emitting events by the Spout.
The Scheme interface declares the methods deserialize(byte[] pojoBytes) for deserializing the event collected. It returns a list of objects instead of just one object as one event could potentially be serialized into several data fields. Here the StockAvroScheme emits the complete Stock object in one field. The second method that needs to be implemented by the Scheme interface is the getOutputFields() method. This method is responsible for advertising the field definition to the receiving bolts. As by the implementation below the stock object gets send in one field.
public class StockAvroScheme implements Scheme {
private static final Logger LOG = LoggerFactory.getLogger(Stock.class);
// deserializing the message recieved by the Spout
public List<Object> deserialize(byte[] pojoBytes) {
StockAvroSerializer serializer = new StockAvroSerializer(); // Kryo Serializer
Stock stock = serializer.read(null, new Input(pojoBytes), Stock.class);
List<Object> values = new ArrayList<>();
values.add(0, stock);
return values;
}
// defining the output fields of the Spout
public Fields getOutputFields() {
return new Fields(new String[]{ FieldNames.STOCK_FIELD });
}
}
This Scheme can be as illustrated below by the YAML topology configuration using Storm Flux:
components:
# defines a scheme for the spout to emit a Stock.class object
- id: "stockAvroScheme"
className: "storm_hive_streaming_example.serializer.StockAvroScheme"
# adding the defined stock scheme to the multi-scheme that can be assigned to the spout
- id: "stockMultiScheme"
className: "backtype.storm.spout.SchemeAsMultiScheme"
constructorArgs:
- ref: "stockAvroScheme"
- id: "zkHosts"
className: "storm.kafka.ZkHosts"
constructorArgs:
- "${hive-streaming-example.zk.hosts}"
# configuring the spout to read bytes from Kafka and emit Stock.class
- id: "stockSpoutConfig"
className: "storm.kafka.SpoutConfig"
constructorArgs:
- ref: "zkHosts" # brokerHosts
- "${hive-streaming-example.kafka.topic}" # topic
- "${hive-streaming-example.kafka.zkRoot}" # zkRoot
- "${hive-streaming-example.kafka.spoutId}" # id
properties:
- name: "scheme"
ref: "stockMultiScheme" # use the stock scheme previously defined
Last but not least we still need to register our customer serializer with Storm.
Registering the Serializer
Tuples are send to Spouts and Bolts running in a separate JVMs either on the same or on a remote host. In case of sending the tuple it needs to get serialized and deserialized prior to placing the tuple on the the output collector. For the serialization Storm uses Kryo Serializer.
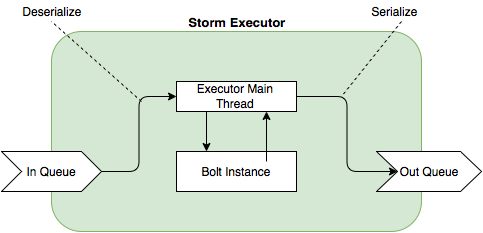
In order to use a custom Serializer implementation it needs to get registered with the Kryo instance being used by Strom. This can be done as part of the topology configuration. Here is the configuration definition using Storm Flux:
name: "hive-streaming-example-avro-scheme"
config:
topology.workers: 1
# define serializers being used by tuples de-/serializing values. See http://storm.apache.org/documentation/Serialization.html
topology.kryo.register:
- storm_hive_streaming_example.model.Stock: storm_hive_streaming_example.serializer.StockAvroSerializer
With this registration of the custom Kryo Serializer the AvroStockDataBolt can simply cast the Stock object from the tuple value emit it to the FieldEmitBolt, which decomposes the Stock instance into separate field being used by the HiveBolt. Having the AvroStockDataBolt and FieldEmitBolt would not make sense in a real implementation as the Scheme could obviously already be configured to do all that – deserialize and emit fields to the HiveBolt. Having these two extra bolts is just for demonstration purposes.
Finally the custom Kryo Serializer which implements a write(Kryo kryo, Output output, Stock object) and read(Kryo kryo, Input input, Class<Stock> type). Having a general implementation of generic Avro types would be ideal.
public class StockAvroSerializer extends Serializer<Stock> {
private static final Logger LOG = LoggerFactory.getLogger(StockAvroSerializer.class);
private Schema SCHEMA = Stock.getClassSchema();
public void write(Kryo kryo, Output output, Stock object) {
DatumWriter<Stock> writer = new SpecificDatumWriter<>(SCHEMA);
ByteArrayOutputStream out = new ByteArrayOutputStream();
BinaryEncoder encoder = EncoderFactory.get().binaryEncoder(out, null);
try {
writer.write(object, encoder);
encoder.flush();
} catch (IOException e) {
LOG.error(e.toString(), e);
}
IOUtils.closeQuietly(out);
byte[] outBytes = out.toByteArray();
output.writeInt(outBytes.length, true);
output.write(outBytes);
}
public Stock read(Kryo kryo, Input input, Class<Stock> type) {
byte[] value = input.getBuffer();
SpecificDatumReader<Stock> reader = new SpecificDatumReader<>(SCHEMA);
Stock record = null;
try {
record = reader.read(null, DecoderFactory.get().binaryDecoder(value, null));
} catch (IOException e) {
LOG.error(e.toString(), e);
}
return record;
}
}
Further Readings
- Storm Serialization
- Storm Hive Streaming Example (Github)
- Storm Flux
- Avro Specification
- Kafka Storm Starter (Github)
- Kryo Serializable
- http://www.confluent.io/blog/stream-data-platform-2/
- Simple Example Using Kryo
- Storm Blueprints: Patterns for Distributed Realtime Computation (Amazon)
- Storm Applied: Strategies for Real-Time Event Processing (Amazon)
