With a broadcast join one side of the join equation is being materialized and send to all mappers. It is therefore considered as a map-side join which can bring significant performance improvement by omitting the required sort-and-shuffle phase during a reduce step. In this Post we are going to discuss the possibility for broadcast joins in Spark DataFrame and RDD API in Scala.
To improve performance of join operations in Spark developers can decide to materialize one side of the join equation for a map-only join avoiding an expensive sort an shuffle phase. The table is being send to all mappers as a file and joined during the read operation of the parts of the other table. As the data set is getting materialized and send over the network it does only bring significant performance improvement, if it considerable small. Another constraint is that it also needs to fit completely into memory of each executor. Not to forget it also needs to fit into the memory of the Driver!
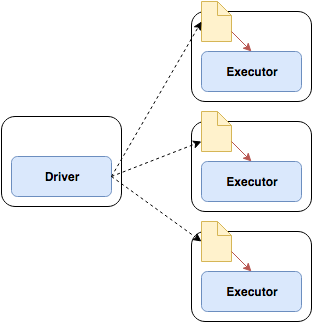
In Spark broadcast variables are shared among executors using the Torrent protocol. The Torrent protocol is a Peer-to-Peer protocol which is know to perform very well for distributing data sets across multiple peers. The advantage of the Torrent protocol is that peers share blocks of a file among each other not relying on a central entity holding all the blocks.
In a previous blog post we’ve already discussed the different Hive Join Strategies available for MapReduce processing. This also applies for Spark as for this blog post we only discuss the broadcast join. The bucket join discussed for Hive is another quick map-side only join and would relate to the co-partition join strategy available for Spark
Sample Date
For this example we are using a simple data set of employee to department relationship. Employees of a imaginary company are assigned to one department they work for which is referenced by an ID (depID). As we have just a few departments but multiple employees we will pick the department table for broadcasting.

We can use Spark RDD parallelize to quickly turn our sample data into a RDD and with toDF to DataFrame as well:
case class Employee(name:String, age:Int, depId: String)
case class Department(id: String, name: String)
val employeesRDD = sc.parallelize(Seq(
Employee("Mary", 33, "IT"),
Employee("Paul", 45, "IT"),
Employee("Peter", 26, "MKT"),
Employee("Jon", 34, "MKT"),
Employee("Sarah", 29, "IT"),
Employee("Steve", 21, "Intern")
))
val departmentsRDD = sc.parallelize(Seq(
Department("IT", "IT Department"),
Department("MKT", "Marketing Department"),
Department("FIN", "Finance & Controlling")
))
val employeesDF = employeesRDD.toDF
val departmentsDF = departmentsRDD.toDF
DataFrame API
The DataFrame API of Spark makes it very concise to create a broadcast variable out of the department DataFrame.
val employeesDF = employeesRDD.toDF
va departmentsDF = departmentsRDD.toDF
// materializing the department data
val tmpDepartments = broadcast(departmentsDF.as("departments"))
employeesDF.join(broadcast(tmpDepartments),
$"depId" === $"id", // join by employees.depID == departments.id
"inner").show()
Below is the output of our broadcast join:
+-----+---+-----+---+--------------------+ | name|age|depId| id| name| +-----+---+-----+---+--------------------+ | Mary| 33| IT| IT| IT Department| | Paul| 45| IT| IT| IT Department| |Peter| 26| MKT|MKT|Marketing Department| | Jon| 34| MKT|MKT|Marketing Department| |Sarah| 29| IT| IT| IT Department| +-----+---+-----+---+--------------------+
You should be able to find the broadcast happening during the execution of the job in the log files. An example output is given below:

Scala API
In Scala we have first to create a pair RDD based from our input file, which will give us the possibility to broadcast the departments table as a Map for quick lookup based on the department id.
val rddTmpDepartment = sc.broadcast(
departmentsRDD.keyBy{ d => (d.id) } // turn to pair RDD
.collectAsMap() // collect as Map
)
Returns -->
rddTmpDepartment:
org.apache.spark.broadcast.Broadcast[
scala.collection.Map[String,Department]] = Broadcast(163)
The broadcast variable can further be used during our map phase returning a joined data set or None:
employeesRDD.map( emp =>
if(rddTmpDepartment.value.get(emp.depId) != None){
(emp.name, emp.age, emp.depId,
rddTmpDepartment.value.get(emp.depId).get.id,
rddTmpDepartment.value.get(emp.depId).get.name)
} else {
None
}
).collect().foreach(println)
The output should look similar to this:
rddTmpDepartment: org.apache.spark.broadcast.Broadcast[scala.collection.Map[String,Department]] = Broadcast(163) (Mary,33,IT,IT,IT Department) (Paul,45,IT,IT,IT Department) (Peter,26,MKT,MKT,Marketing Department) (Jon,34,MKT,MKT,Marketing Department) (Sarah,29,IT,IT,IT Department) None
Further Reading
- Spark in Action (Amazon)
- Learning Spark: Lightning-Fast Big Data Analysis (Amazon)
- Spark Broadcast Variables

I have question about very large size dataframes. I am trying to train a ml model with my df which has about 1 billion rows. Even by using 144 cores and 900gb of ram in total still my script crashes. I was wondering if you know any solution for this.
Thanks
LikeLike
If your training method needs all samples locally, your total memory wouldn’t matter, only the available memory on that one node. Could that be your problem?
LikeLike
val tmpDepartments = broadcast(departmentsDF.as(“departmentsemployeesDF.join(broadcast(tmpDepartments),
$”depId” === $”id”, // join by employees.depID == departments.id
“inner”).show()
above line is correct since i am getting error while running code , Please help me
LikeLike