MarkLogic is one of the leading Enterprise NoSQL vendors that offers through it’s server product a database centered mainly around search. It’s document centric design based on XML makes it attractive for content focused applications. MarkLogic Server combines a transactional document repository with search indexing and an application server.
The underlying data format for all stored documents, which can either be text or binary files, is XML. It’s considered schema-aware as a schema prior to insertion is not required but can be applied afterwards as needed. MarkLogic Server applies a full-text index to the documents stored within it’s repository. Indexes for search are also applied to the paths of the XML structure. This effectively makes documents search able right after insertion. This approach of advanced search around a document based design make it similar to a combination of MongoDB with ElasticSearch.
Developers can get started with MarkLogic Server 7 quite quickly by using Amazon Machine Image (AMI) supplied here. For this post we are going to use that image to build a small search application around the exported posts of this blog. In this post we are going to strive to build a search application solely around MarkLogic Server.
Server Setup
A quick start to MarkLogic Server is provided by a provisioned AMI for developers through the Amazon Marketplace. Start one of this instances in a region of your preference. Make sure to attach an extra EBS (Elastic Block Store) which should get mounted to /dev/xvdf . This extra block storage is used by the server’s repository and depending on you use case should have enough storage provided. It is important to have this device mounted to your instance prior to startup as the server otherwise will not start. In addition to the storage you should take care to have access to the required ports. Ideally you open up the port range 7997 – 8100 TCP to your network while only 8001 (dashboard) and 8000 (admin) are required to begin with. The reason to open up more ports is due to the fact that applications and other services are run on there own port. You can start out but open just the two ports at the beginning, adding ports to the security groups as you go.
After a successful start of the machine you should be able to access the admin console by directing your browser to [EC2-IP]:8001 . The dashboard can be reached under 8000 . If something went wrong or you otherwise have the need to access the machine and server directly you ought to be able to login via ssh using the certificate you choose during the startup with the follwoing command ssh -i ~/.ssh/your-cert.pem ec2-user@[EC2-IP] . MarkLogic Server is installed under /opt/MarkLogic while the database files are stored under /var/opt/MarkLogic . You seldom should have the need to access the database files directly. To stop, start, or request the status of MarkLogic you can use /etc/init.d/MarkLogic to do so.
Importing with Content Pump
For this blog post I have decided to use the exported post of this blog. To export the blog posts from WordPress I used the export tool provided by WordPress. The posts are already exported in XML which is a benefit for the current use case but MarkLogic Server supports any kind of text or binary file.
To upload the posts to the database I have decided to try the fairly new MarkLogic Content Pump which is a Hadoop based implementation to import data in a distributed fashion to the server. It support different kind of files and storages and also a pluggable way to transform the data during import. Download the mlcp binary to use it for importing the data to the server.
Prior to importing the post we obviously need a database to store them. In addition to that mlcp makes use of a XDBC (XML Database Connector) service to import the data. We will use the port of this service as a crucial import for mlcp. Create a database by going to the admin console (port: 8001). Under Database you’ll find a Create tile to add a new database. For now we’ll just give it a name, for example wordpress, and leave the other settings defaults. After you have created the database you’ll need to assign a so called Forest to it. A Forest is the index structure to each document in the database and is required to make the documents search able. The name is probably related to the fact that it treats all documents as root and many roots are a forest, aren’t they?
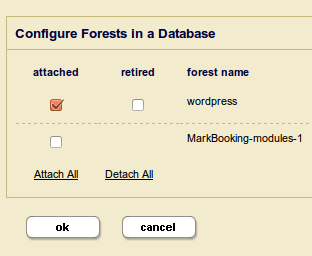
Create a forest under Forest in the admin console and assign it to the database. You should be able to find a “apply a forest” link under the database you have created. In the end it should look something like this:
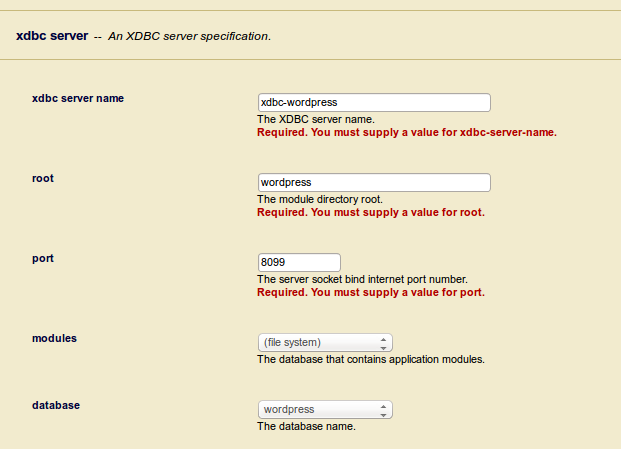
The XDBC service can be created under Groups > Defaults > App-Services using the Create XDBC tile. It’s important to choose the same database as we’ve created in the step before. Other than that it’s you’ll have to provide a name and port to the service. Your setting might in the end look something like this:
 We now should be able to import the data using the mlcp command. We can use the following command to get started with our search app:
We now should be able to import the data using the mlcp command. We can use the following command to get started with our search app:
mlcp.sh import -host [EC2-IP] -port 8099 -username user -password pw -input_file_path henning039sweblog.wordpress.2014-07-06.xml -namespace http://wordpress/posts -input_file_type xml -output_uri_prefix /posts/ -output_uri_suffix .xml -mode local -output_uri_replace "/home/hkropp/Downloads/henning039sweblog.wordpress.2014-07-06.xml,'weblog.2014-07-06.xml'"
I have to leave you with the documentation of mlcp for most of the parameters used here. Most of the parameters are designed around the approach to transform the output into a nice structure that will later benefit us. This also means that they are almost not necessary to begin with. For a quick start you are probably better of leaving most of this parameters a side and refer to the documentation at some later point.
We now have you posts within MarkLogic Server and ready to be retrieved. Underneath all this the post have been fully indexed by the database. This means that for our simple search App no further preparation is needed. So let’s build a small App.
XQuery Search Application
MarkLogic Server combines a database with an application server. We are going to be able to build our application by configuring a service within the admin console already used in the prior steps. A folder will be created where we can store our application logic scripts. For testing and debugging the API we are going to use, it’s a great way to start by using the Query Builder which is part of the server dashboard (port: 8000). Just point your browser to the following address EC2-IP:8000 .
The foundation of accessing the data in a MarkLogic repository is XQuery. Being a functional language to access data, XQuery is quite a powerful language rendering XML as a result of each query that can easily be rendered as HTML by a web browser. This means that for building an application like the one from this post no further concepts or technology stacks are required. This is a very mature design on top of XML, but MarkLogic is often criticized for being dependent on XQuery, while it’s really powerful it seems not to attract much developers.
By now MarkLogic Server can be accessed in many different ways for example using REST. Also a JavaScript API has been developed to attract a broad band of JS developers. An SQL API makes it possible to seamlessly integrate the search capabilities into modern BI tools.
For this post I am going to use the XQuery API and demonstrate it’s use by a simple example of the search API provided.
Creating an Application Server
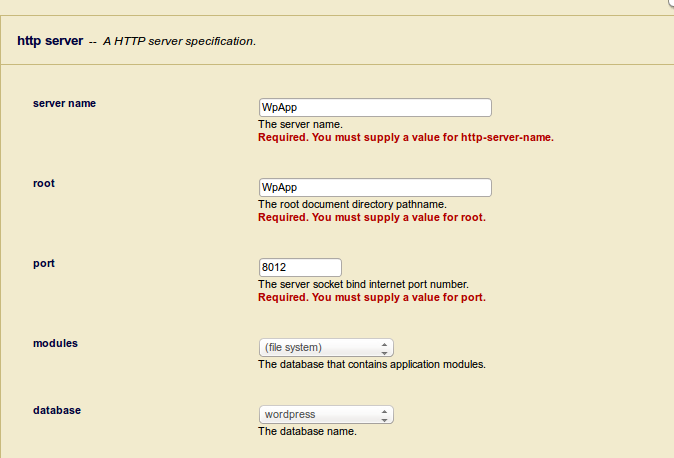
To create our application server we once again refer Groups > Default > App Servers. Here we’ll find the Create HTTP tile which will create for us a HTTP service that is capable of serving XQuery files to the client. A directory has to be created within the server installation named after the root. In our case /opt/MarkLogic contains the directory WpApp. Once again we’ll not touch most the configuration possibilities given this application setup:
The Application
Having setup the application server we can now get started to develop our application using XQuery. The application will be accessible using port 8012 in our web browser. Prior to writing your first code it is always a good idea to test it within the Query console within in the dashboard.
A basic query to list all posts in descending order can for example be tested within the query console and would look like this:
xquery version "1.0-ml"; declare namespace psts = "http://wordpress/posts"; for $post in /psts:rss/psts:channel/psts:item order by xs:string(($post/psts:pubDate)[1]) descending return $post/psts:title/text()
The query console gives us the possibility to test for example whether we can order by xs:date or xs:string . The later here is the case as we did not define that pubDate should be of type date.
In our sample application we’ll use part of this query to make an index file to show the user a list of the most recent post. In addition to that we’ll elaborate a small example based on the search API by giving the user a search form.
The search API of MarkLogic Server is quite sophisticated to use by providing an overwhelming amount of options to configure. A good overview provides the 5 min walk through you can find here. In our case if we would like to make the posts search able we have to constrain the search to the item element in the document. In our case to query for all the post containing a certain key word the following query can be used:
xquery version "1.0-ml";
declare namespace psts = "http://wordpress/posts";
import module namespace
search = "http://marklogic.com/appservices/search"
at "/MarkLogic/appservices/search/search.xqy";
let $search_term := "hadoop"
let $options :=
<options xmlns="http://marklogic.com/appservices/search">
<constraint name="items">
<element-query name="item" ns="http://wordpress/posts" />
</constraint>
</options>
return search:search(concat("items:",$search_term), $options)
We can use the above script for our application to display search results of our blog posts to the client. Below you find the complete sources of the application that can be deployed to the create application server by storing them into the created folder.
The index file:
xquery version "1.0-ml";
(: index.xqy 🙂
declare namespace psts = "http://wordpress/posts";
<html lang="en" xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta charset="utf-8"/>
<meta http-equiv="X-UA-Compatible" content="IE=edge"/>
<meta name="viewport" content="width=device-width, initial-scale=1"/>
<meta name="description" content=""/>
<meta name="author" content=""/>
<link rel="stylesheet" href="//maxcdn.bootstrapcdn.com/bootstrap/3.2.0/css/bootstrap.min.css"/>
<link rel="stylesheet" href="//maxcdn.bootstrapcdn.com/bootstrap/3.2.0/css/bootstrap-theme.min.css"/>
//maxcdn.bootstrapcdn.com/bootstrap/3.2.0/js/bootstrap.min.js
</head>
<body role="document">
<!-- Fixed navbar -->
</div>
</div>
Search
<button type="submit" class="btn btn-primary btn-lg">Search</button>
</form>
</div>
Posts (# { count(/psts:rss/psts:channel/psts:item) })
<p>
{
for $post in /psts:rss/psts:channel/psts:item order by xs:string(($post/psts:pubDate)[1]) descending
return
}
</p>
</div>
</body>
</html>
The search:
xquery version "1.0-ml";
(: search.xqy 🙂
declare namespace psts = "http://wordpress/posts";
import module namespace
search = "http://marklogic.com/appservices/search"
at "/MarkLogic/appservices/search/search.xqy";
let $search_term := xdmp:get-request-field("s")
let $options :=
<options xmlns="http://marklogic.com/appservices/search">
<constraint name="items">
<element-query name="item" ns="http://wordpress/posts" />
</constraint>
</options>
<html lang="en" xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta charset="utf-8"/>
<meta http-equiv="X-UA-Compatible" content="IE=edge"/>
<meta name="viewport" content="width=device-width, initial-scale=1"/>
<meta name="description" content=""/>
<meta name="author" content=""/>
<link rel="stylesheet" href="//maxcdn.bootstrapcdn.com/bootstrap/3.2.0/css/bootstrap.min.css"/>
<link rel="stylesheet" href="//maxcdn.bootstrapcdn.com/bootstrap/3.2.0/css/bootstrap-theme.min.css"/>
//maxcdn.bootstrapcdn.com/bootstrap/3.2.0/js/bootstrap.min.js
</head>
<body role="document">
<!-- Fixed navbar -->
</div>
</div>
Results
<p>
{
return search:search(concat('items:',$search_term), $options)
}
</p>
</div>
</body>
</html>
By placing both files under the created WpApp directory we have successfully deployed our first sample search application using MarkLogic Server.
Further Readings
 Published
Published
