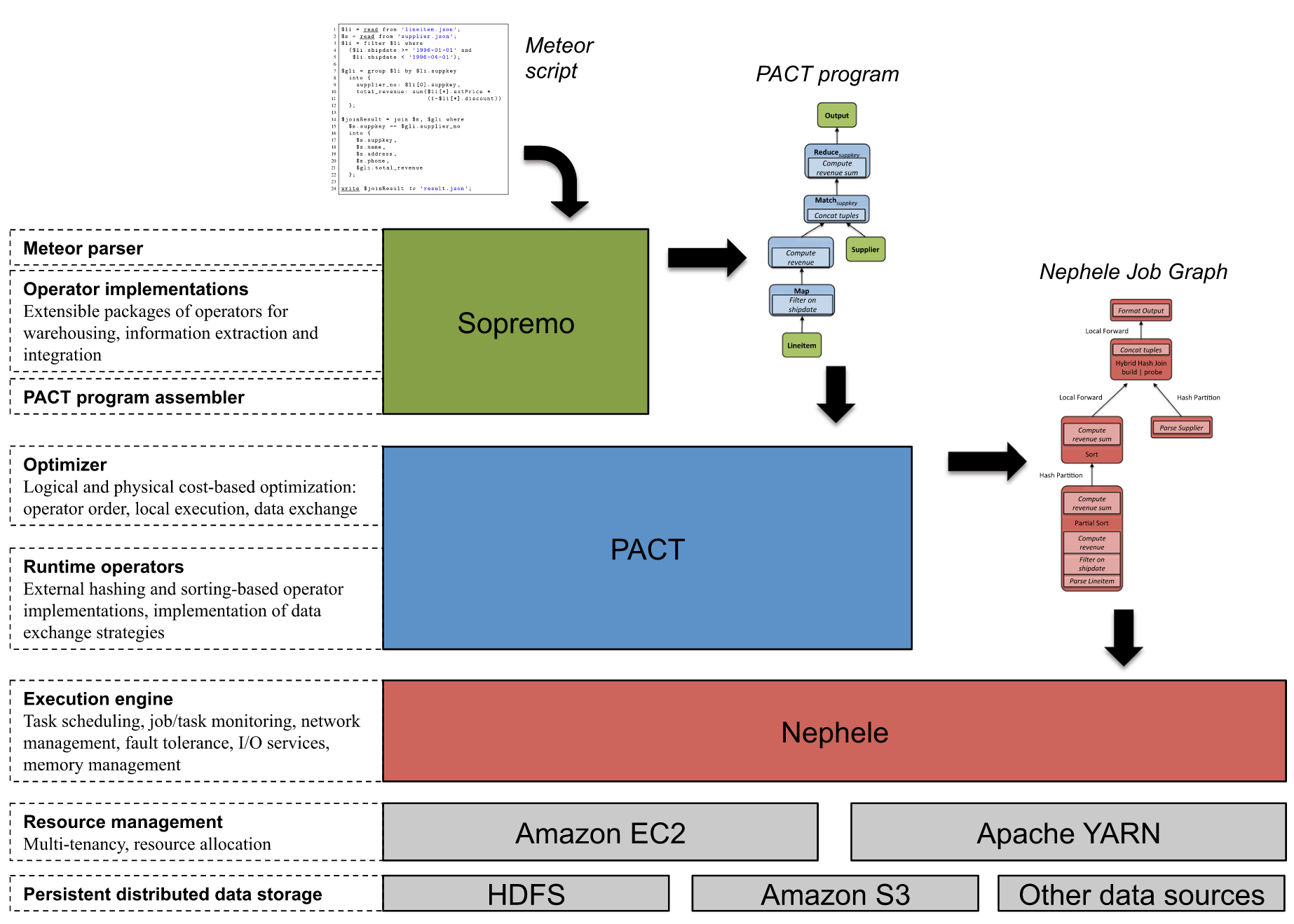
Data visualization is an integral part of data science. The programming language Scala has many characteristics that make it popular for data science use cases among other languages like R and Python. Immutable data structures and functional constructs are some of the features that make it so attractive to data scientists. Popular big data crunching frameworks like Spark or Flink do have their fair share on an ever growing ecosystem of tools and libraries for data analysis and engineering. Scala is particularly well suited to build robust libraries for scalable data analytics.
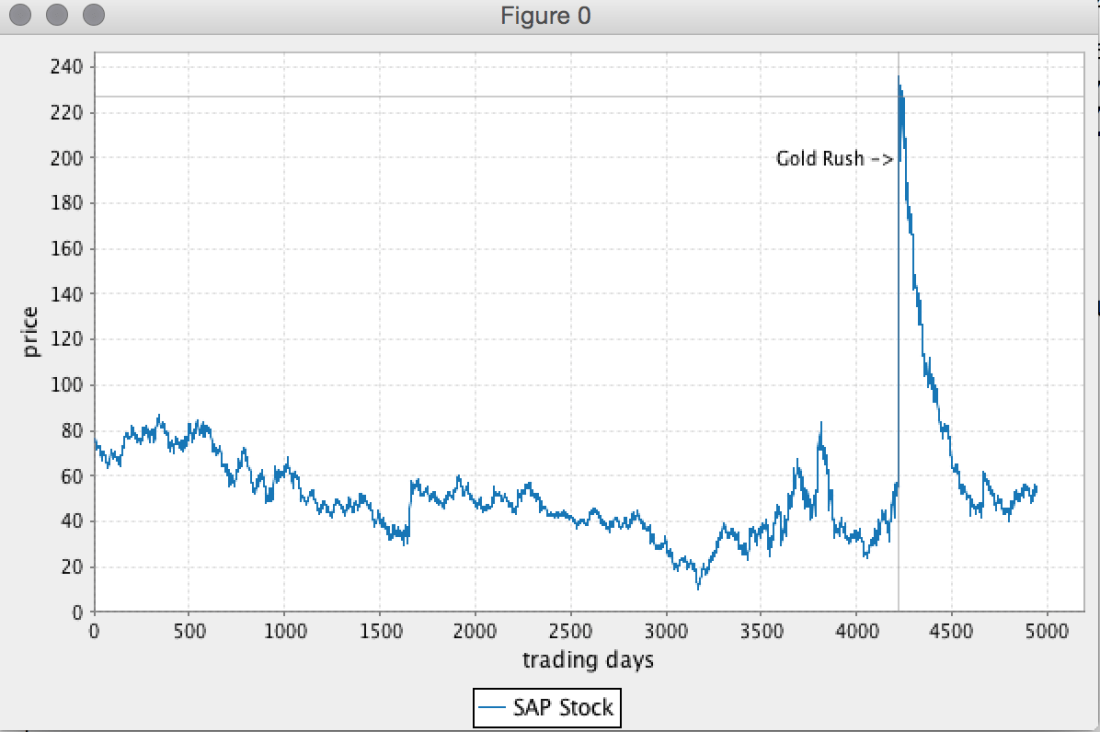
In this post we are going to introduce Breeze, a library for fast linear algebraic manipulation of data sets, together with tools for visualization and NLP. Starting with basic creation of vectors, we will create an application for plotting stock prices. The stock data is obtained form Yahoo Finance, but can also be downloaded here for SAP, YAHOO, BMW, and IBM. Continue reading “Plotting Graphs – Data Science with Scala”