Flume![]() is a distributed system to aggregate log files into the Hadoop Distributed File System (HDFS). It has a simple design of Events, Sources, Sinks, and Channels which can be connected into a complex multi-hop architecture.
is a distributed system to aggregate log files into the Hadoop Distributed File System (HDFS). It has a simple design of Events, Sources, Sinks, and Channels which can be connected into a complex multi-hop architecture.
While Flume is designed to be resilient “with tunable reliability mechanisms for fail-over and recovery” in this blog post we’ll also look at the reliable forwarding of rsyslog, which we are going to use to store postfix logs in Amazon S3.
A basic design of aggregating postifx log files could look like the following diagram:
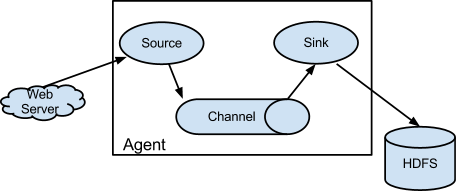 In this scenario our Mail (Web) Server emits events to our Flume Agent (Source) which writes this events to a Channel. Our channel stacks this events and the Sink then picks them up and finally writes the events to S3 (HDFS). So for this scenario we would only need to define a Flume Source, Sink, and Channel to collect our postfix logs with a Sink writing to S3.
In this scenario our Mail (Web) Server emits events to our Flume Agent (Source) which writes this events to a Channel. Our channel stacks this events and the Sink then picks them up and finally writes the events to S3 (HDFS). So for this scenario we would only need to define a Flume Source, Sink, and Channel to collect our postfix logs with a Sink writing to S3.
Setting Up Flume
Setting up Flume to use Simple Storage Service (S3) is quite simple as we can use the HDFS Sink of Flume and Hadoop’s capability to “natively” write to S3. Prior to using this Hadoop needs to be setup and installed on your system. For setting up Hadoop please read here or here. Please be aware that we don’t need any of the daemons running, we just need the libraries and the configuration!!
To configure S3 as the default file system for Hadoop we can change the configuration in mapred-site.xml accordingly:
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>fs.default.name</name> <value>s3n://AWS_KEY_ID:AWS_SECRET_ACCESS_KEY@BUCKET_NAME</value> </property> </configuration>
This should be enough to make Hadoop use S3 as it’s underlaying file storage. If setup correctly you should also be able to use hadoop fs to browse your S3 bucket
hadoop fs -ls
You can also always override the default file system at command prompt using -fs flag to try out different settings. If you don’t succeed in configuring Hadoop to use S3 try to make it work this way and then change the configuration:
hadoop fs -fs s3n://AWS_KEY_ID:AWS_SECRET_ACCESS_KEY@BUCKET_NAME -ls /
S3 Postfix Flume Agent
Next we are going to configure a Flume agent that we can use to collect postfix logs. Our agent will consists of a Source collecting syslogs events listening on a certain port, a Channel the Source can write to and a Sink picking up logs from the channel and writing them into S3 (HDFS).
We’ll run a single agent and the channel is going to be a memory channel which both are rather not very reliable designs. As it is important to build up a system to be robust from the ground up in our scenario we’ll heavily rely on a reliable setup of rsyslog. Skip ahead if you want to read more about that.
Our source is going to listen for syslog events on port 5140:
postfix.sources.syslog_tcp.type = multiport_syslogtcp # tcp for reliable connection postfix.sources.syslog_tcp.host = 0.0.0.0 postfix.sources.syslog_tcp.ports = 5140
Our sink is going to use HDFS and write into the /postfix folder. We’ll store all the logs in a folder hierarchy containing the hostname (IP) and day (Y-m-d). All files will also have a mail_log prefix. To actually use the hostname and day of the the event Flume Interceptors are used, which populate the event header at the source. Our sink:
postfix.sinks.s3.type = hdfs
postfix.sinks.s3.hdfs.path = /postfix/%{hostname}/%y-%m-%d
postfix.sinks.s3.hdfs.filePrefix = mail_log
Flume Intercetpor to populate event headers with host and day:
postfix.sources.syslog_tcp.interceptors = i1 i2 postfix.sources.syslog_tcp.interceptors.i1.type = timestamp postfix.sources.syslog_tcp.interceptors.i2.type = host postfix.sources.syslog_tcp.interceptors.i2.hostHeader = hostname
The interceptor is part of our source and helps to write the event headers we can use when storing the event to the file system.
As already mentioned the channel is going to be a simple memory channel which is designed for high throughput and little resilience. All in all our Flume agent looks like this:
postfix.sources = syslog_tcp
postfix.sinks = s3
postfix.channels = mem_channel
postfix.sources.syslog_tcp.type = multiport_syslogtcp
postfix.sources.syslog_tcp.host = 0.0.0.0
postfix.sources.syslog_tcp.ports = 5140
#postfix.sources.syslog_tcp.interceptors = i1 i2
#postfix.sources.syslog_tcp.interceptors.i1.type = timestamp
#postfix.sources.syslog_tcp.interceptors.i2.type = host
#postfix.sources.syslog_tcp.interceptors.i2.hostHeader = hostname
postfix.sinks.s3.type = hdfs
postfix.sinks.s3.hdfs.path = /postfix/%{hostname}/%y-%m-%d
postfix.sinks.s3.hdfs.filePrefix = mail_log
postfix.channels.mem_channel.type = memory
postfix.channels.mem_channel.capacity = 1000
postfix.channels.mem_channel.transactionCapacity = 100
postfix.sources.syslog_tcp.channels = mem_channel
postfix.sinks.s3.channel = mem_channel
We can now run this agent and test it by connecting to it with telenet:
flume-ng agent -c flume_example -f flume_example/flume_postfix.conf --name postfix -Dflume.root.logger=INFO,console &
To test if everything is working correctly we can connect to the running Flume agent using telnet and write “events” to it. If working correctly files containing syslog events serialized as Sequence Files should appear in the configures bucket.
echo "Flume Example Postfix" | telnet localhost 5140
Setup rsyslog
We now have our Flume agent running collecting syslog events that are directed to port 5140. Configuring rsyslog to send postfix messages to that port is a simple line in the configuration. But we also would want rsyslog to do this in a reliable way. If your Flume agent dies we would want rsyslog to spill the events to a temporary output and as soon as the agent is running again to send this queued messages. This can be achieved by using a so called ActionQueue. This is going to be our cornerstone of reliability. For an in-depth reading of rsyslog ActionQueues please read here.
$ActionQueueType LinkedList # use asynchronous processing $ActionQueueFileName flume_postfix # set file name, also enables disk mode $ActionResumeRetryCount -1 # infinite retries on insert failure $ActionQueueSaveOnShutdown on # save in-memory data if flume shuts down mail.* @@localhost:5140 # filter message only send mail/postfix messages
To configure rsyslog you create a *.conf file under /etc/rsyslog.d . Please check if $IncludeConfig /etc/rsyslog.d/*.conf is present in /etc/rsyslog.conf to be sure your config file is going to be read. In my case I simply used /etc/rsyslog.d/50-default.conf where the filters for mail.* were already present.
You can see in the configuration I use that through rsyslog ActionQueues messages are stacked if failed to send to port 5140 on localhost. You should note that lines starting with the word “Action” modify the next action and should be specified in front of it (/usr/share/doc/rsyslog-doc/html/rsyslog_conf_global.html). In our case we modify the mail.* @@localhost:5140 action to use a LinkedList.
rsyslog will notice if the Flume agent is down, as we are using TCP. This would not be possible if using UDP.

Reliably Store Postfix Logs in S3 with Apache Flume and rsyslog http://t.co/J5Ti8Psg8Z
LikeLike