While at it’s core TensorFlow is a distributed computation framework besides the official HowTo there is little detailed documentation around the way TensorFlow deals with distributed learning. This post is an attempt to learn by example about TensorFlow’s distribution capabilities. Therefor the existing MNIST tutorial is taken and adapted into a distributed execution graph that can be executed on one or multiple nodes.
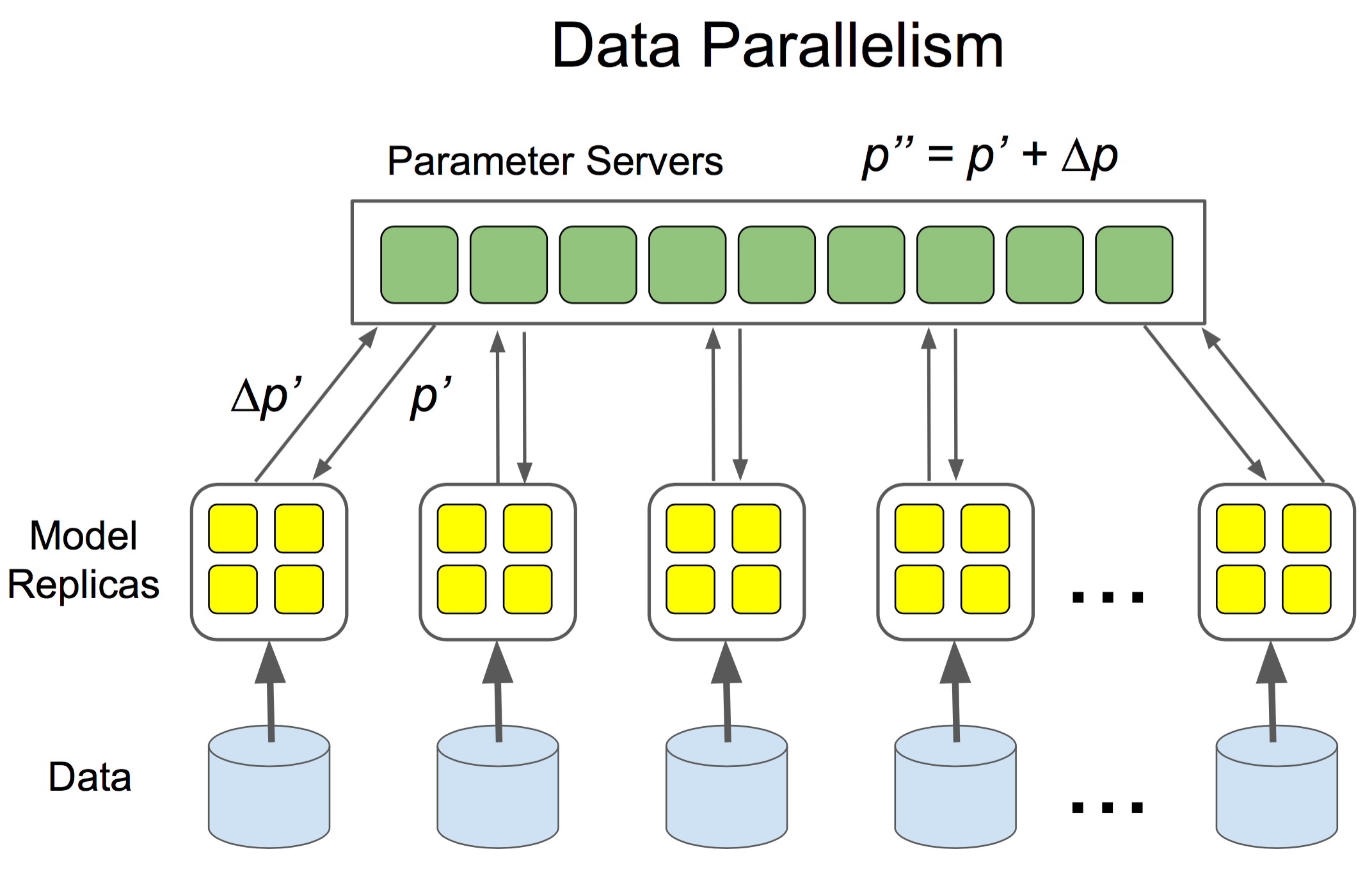
The framework offers two basic ways for distributed training of a model. In the simplest form the same data and computation graph is executed on multiple nodes in parallel on batches of the replicated data. This is known as Between-Graph Replication. Each worker updates the parameters of the same model, which means that each of the worker nodes are sharing a model. Updates to the shared model get averaged before being applied, this is at least the case for the synchronous training of a distributed model. In case of an asynchronous training the workers update the shared model parameters independently of each other. While the asynchronous training is known to be faster, the synchronous training proofs to provide more accuracy.
But there is also another way in which TensorFlow is able to distribute it’s computation. In case of the In-Graph Replication distribution there is only one client that contains the model parameters and assigns the compute intensive calculation of the model to specific worker tasks, essentially working like a resource manager. Between-Graph Replication is the most common distribution model one finds on the internet.

Kind of Processes
Let’s quickly touch on the different responsibilities or roles a process in the TensorFlow framework can take on. For one in each TensorFlow graph there is at least one client. The client essentially executes the graph computation by connecting to a local or remote Session. For distribution the client would connect to a Master service, which is responsible for distributing the processing among worker nodes. Finally there are the workers which does the actual computation, hereby it is helpful to understand that TensorFlow is a general purpose computation framework, so this computation can be almost anything defined as a step inside the computation graph of the client.
In the case of multiple clients running simultaneously (eg. Between-Graph Replication) each client would also run initialization step like parameter initialization. That is not only a waste of resources but would in an asynchronous execution lead to unexpected results. For this to not happen TensorFlow assigns to one of the workers a special role for doing the initialization steps for all clients once, that role is the role of the chief worker.
Distributed MNIST
Here we are taking the simple MNIST example from the TensorFlow tutorial and adapted it to run in a distributed way. For testing and demonstration purposes the code can be executed on the same machine.
Taks or processes that belong to a execution graph in TensorFlow are considered a cluster. Each task in a cluster can take one of the previously defined roles. In the below example the cluster has a set of Parameter Server (ps) and Workers (workers) which are given by a comma separated list of hostnames + ports.
ps_hosts = FLAGS.ps_hosts.split(",")
worker_hosts = FLAGS.worker_hosts.split(",")
cluster = tf.train.ClusterSpec({
"ps": ps_hosts,
"worker": worker_hosts
})
server = tf.train.Server(
cluster,
job_name = FLAGS.job_name,
task_index = FLAGS.task_index
)
For us to run this on a single machine we could execute it like this multiple times for each participating process. To be distinguishable each task has an assigned index.
python dist_minst_softmax.py
--ps_hosts=localhost:2222,localhost:2223
--worker_hosts=localhost:2224,localhost:2225
--job_name=worker —task_index=1
During the execution of the script we also define via the –job_name parameter which role the process takes. Parameter Servers (ps) simply join the Session, while workers depending on the kind of distribution execute different aspects of the graph calculation.
if FLAGS.job_name == "ps": server.join() elif FLAGS.job_name == "worker": ...
The parameter service processes share and coordinate accumulated updates to the parameters of the model. A worker process executes a specific task as part of the graph execution. We already discussed that with Between-Graph replication each worker processes the same training on a batch of input data. It is probably the most common distributed training mode one can find on the internet and is also demonstrated here. Thereby each worker has it’s own client and graph of execution sharing model parameters while executing computation on a batch of input data
# run session or wait for init
with sv.prepare_or_wait_for_session(server.target) as sess:
for _ in range(100):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step,
feed_dict={x: batch_xs, y_: batch_ys})
print(sess.run(accuracy,
feed_dict={x: mnist.test.images, y_: mnist.test.labels}))
The supervisor takes care of session initialization, restoring from a checkpoint, and closing when done or an error occurs. It is also responsible for initialising the session, like the parameters, for all workers.
sv = tf.train.Supervisor(
is_chief=(FLAGS.task_index == 0),
global_step=global_step,
init_op=init_op)
Running this on one or multiple machines the following commands have to be executed on each machine or multiple times on the same machine. One would need to adapt the IP address in the following commands:
python dist_mnist_softmax.py --ps_hosts=localhost:2222,localhost:2223 --worker_hosts=localhost:2224,localhost:2225 --job_name=ps --task_index=0 python dist_mnist_softmax.py --ps_hosts=localhost:2222,localhost:2223 --worker_hosts=localhost:2224,localhost:2225 --job_name=ps --task_index=1 python dist_mnist_softmax.py --ps_hosts=localhost:2222,localhost:2223 --worker_hosts=localhost:2224,localhost:2225 --job_name=worker --task_index=0 python dist_mnist_softmax.py --ps_hosts=localhost:2222,localhost:2223 --worker_hosts=localhost:2224,localhost:2225 --job_name=worker --task_index=1
The complete code of a softmax MNIST training in a distributed TensorFlow graph can be found below:
"""
A simple MNIST classifier.
"""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import argparse
import sys
from tensorflow.examples.tutorials.mnist import input_data
import tensorflow as tf
FLAGS = None
def main(_):
ps_hosts = FLAGS.ps_hosts.split(",")
worker_hosts = FLAGS.worker_hosts.split(",")
cluster = tf.train.ClusterSpec({"ps": ps_hosts, "worker": worker_hosts })
server = tf.train.Server(cluster,
job_name=FLAGS.job_name,
task_index=FLAGS.task_index)
if FLAGS.job_name == "ps":
server.join()
elif FLAGS.job_name == "worker":
with tf.device(tf.train.replica_device_setter(
worker_device="/job:worker/task:%d" % FLAGS.task_index,
cluster=cluster)):
global_step = tf.contrib.framework.get_or_create_global_step()
with tf.name_scope("input"):
mnist = input_data.read_data_sets("./input_data", one_hot=True)
x = tf.placeholder(tf.float32, [None, 784], name="x-input")
y_ = tf.placeholder(tf.float32, [None, 10], name="y-input")
tf.set_random_seed(1)
with tf.name_scope("weights"):
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
with tf.name_scope("model"):
y = tf.matmul(x, W) + b
with tf.name_scope("cross_entropy"):
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y))
with tf.name_scope("train"):
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
with tf.name_scope("acc"):
init_op = tf.initialize_all_variables()
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
sv = tf.train.Supervisor(is_chief=(FLAGS.task_index == 0),
global_step=global_step,
init_op=init_op)
with sv.prepare_or_wait_for_session(server.target) as sess:
for _ in range(100):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
print(sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.register("type", "bool", lambda v: v.lower() == "true")
# Flags for defining the tf.train.ClusterSpec
parser.add_argument(
"--ps_hosts",
type=str,
default="",
help="Comma-separated list of hostname:port pairs"
)
parser.add_argument(
"--worker_hosts",
type=str,
default="",
help="Comma-separated list of hostname:port pairs"
)
parser.add_argument(
"--job_name",
type=str,
default="",
help="One of 'ps', 'worker'"
)
# Flags for defining the tf.train.Server
parser.add_argument(
"--task_index",
type=int,
default=0,
help="Index of task within the job"
)
FLAGS, unparsed = parser.parse_known_args()
tf.app.run(main=main, argv=[sys.argv[0]] + unparsed)

Interesting post. How complicated is it to add a new worker host? Is there any kind of ambari integration available or in the pipeline?
LikeLike
Hello,
Thanks for your blog on
When I run your code – same processing happens occurs on both worker nodes. 20 Epocs run on both worker nodes.
Ideally with distributed processing we expect compute or data decomposition so that processing completes fast.
What should I change in code for this to happen?
Regards
LikeLike
Just a heads up, Supervisor is deprecated now and MonitoredTrainingSession should be used instead. See https://www.tensorflow.org/api_docs/python/tf/train/Supervisor.
LikeLike